«`html
Language models (LMs) and the Challenges of Machine Unlearning
Модели языка (LMs) сталкиваются с серьезными проблемами, связанными с конфиденциальностью и авторскими правами из-за обучения на огромных объемах текстовых данных. Включение частной и защищенной авторскими правами информации в обучающие наборы данных привело к юридическим и этическим проблемам, включая судебные иски по авторским правам и требования соответствия регулятивным актам, таким как GDPR. Владельцы данных все чаще требуют удаления своих данных из обученных моделей, что подчеркивает необходимость эффективных методов машинного забывания.
Methods for Machine Unlearning in Language Models
Исследователи предприняли различные попытки решить проблемы машинного забывания в моделях языка. Точные методы машинного забывания, направленные на создание модели без забытых данных, были разработаны для простых моделей, таких как SVM и наивные байесовы классификаторы. Однако эти подходы вычислительно невозможны для современных больших моделей языка.
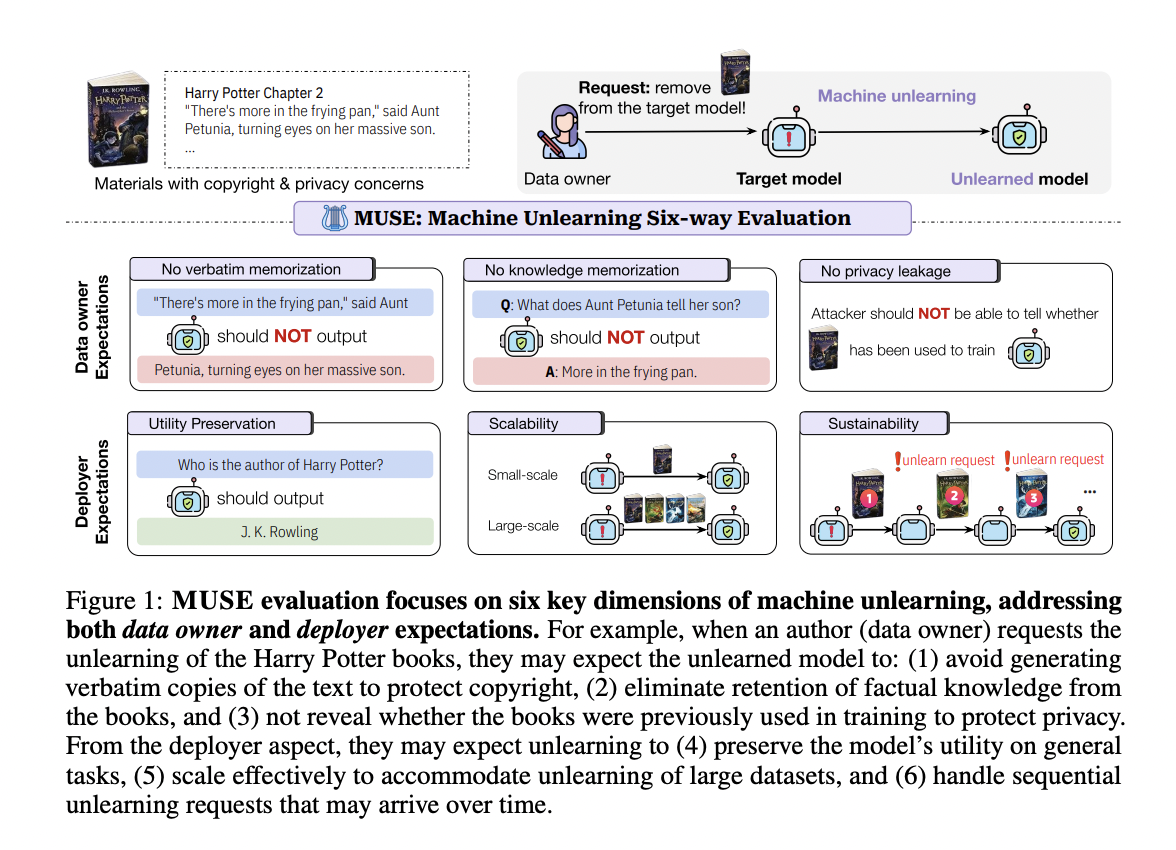
The Introduction of MUSE Framework
Исследователи из нескольких университетов и Google Research представляют MUSE (Machine Unlearning Six-Way Evaluation), комплексную систему оценки, разработанную для оценки эффективности алгоритмов машинного забывания для моделей языка. Этот систематический подход оценивает шесть критических свойств, которые удовлетворяют требованиям как владельцев данных, так и развертывающих модели, для практического забывания. MUSE исследует способность алгоритмов забывания удалять дословное запоминание, запоминание знаний и утечку конфиденциальной информации, а также оценивает их способность сохранять полезность, масштабироваться эффективно и поддерживать производительность при последовательных запросах на забывание.
Evaluation Metrics and Key Criteria of MUSE Framework
MUSE предлагает комплексный набор метрик оценки, которые удовлетворяют ожиданиям как владельцев данных, так и развертывающих модели. Фреймворк состоит из шести ключевых критериев, включая отсутствие дословного запоминания, отсутствие запоминания знаний, отсутствие утечки конфиденциальной информации, сохранение полезности, масштабируемость и устойчивость.
Findings and Recommendations of MUSE Framework
Оценка MUSE восьми методов машинного забывания показала значительные вызовы в области машинного забывания для моделей языка. Большинство методов эффективно удаляли дословное и знаниевое запоминание, но испытывали проблемы с утечкой конфиденциальной информации, а также с масштабируемостью и устойчивостью при последовательных запросах на забывание. Эти результаты подчеркивают значительные компромиссы и ограничения в текущих методах машинного забывания, подчеркивая необходимость более эффективных и сбалансированных подходов для удовлетворения требований как владельцев данных, так и развертывающих модели.
Развитие вашего бизнеса с использованием искусственного интеллекта
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте MUSE: A Comprehensive AI Framework for Evaluating Machine Unlearning in Language Models.
Применение и внедрение ИИ в бизнесе
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI. Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ. Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI. На полученных данных и опыте расширяйте автоматизацию.
Инструменты и решения от Flycode.ru
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Попробуйте ИИ ассистент в продажах здесь. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
«`

























