NeedleBench: Оценка возможностей долгоконтекстных моделей языка (LLM) на русском и китайском языках
Оценка возможностей поиска и рассуждения больших языковых моделей (LLMs) в крайне длинных контекстах, расширяющихся до 1 миллиона токенов, представляет собой значительное испытание. Эффективная обработка длинных текстов критически важна для извлечения актуальной информации и принятия точных решений на основе обширных данных. Эта проблема особенно актуальна для реальных приложений, таких как анализ юридических документов, академических исследований и деловой аналитики. Решение этой проблемы имеет важное значение для продвижения исследований в области искусственного интеллекта, позволяя развивать LLMs способные выполнять сложные задачи в практических сценариях с долгим контекстом.
NeedleBench: новая методика оценки
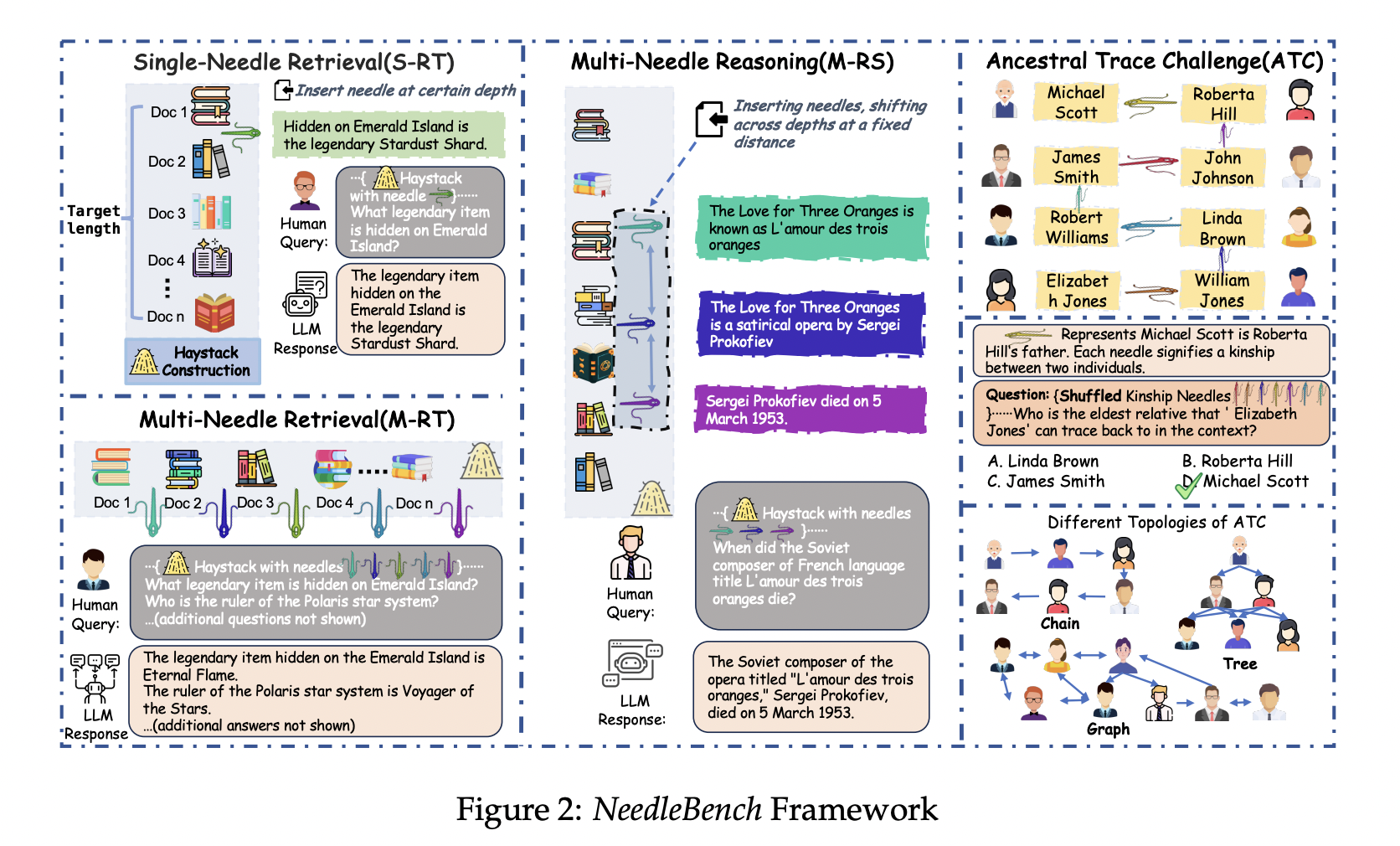
Команда исследователей из Shanghai AI Laboratory и Tsinghua University представляют NeedleBench, новую методику, предназначенную для оценки возможностей долгоконтекстных LLMs на китайском и русском языках. NeedleBench состоит из прогрессивно более сложных задач, включая Задачи одиночного поиска (S-RT), Задачи множественного поиска (M-RT) и Множественные задачи рассуждения (M-RS), направленных на предоставление всесторонней оценки способностей LLMs. Главное новшество — введение вызова предкового следа (ATC), имитирующего реальные задачи рассуждения в долгом контексте. ATC проверяет способности моделей выполнять задачи многократного логического рассуждения. Этот подход представляет собой значительный вклад в область, предлагая более строгую и реалистичную оценку возможностей долгоконтекстных LLMs, а также устраняя ограничения существующих методов.
Результаты исследования
Исследователи представляют комплексные результаты оценки популярных LLMs на задачах NeedleBench при различных длинах токенов. Ключевые метрики производительности включают точность извлечения для задач поиска и точность рассуждения для многократных логических задач. Результаты указывают на значительное пространство для улучшения практического применения текущих LLMs в долгих контекстах. Например, модель InternLM2-7B-200K достигла идеальных результатов в задачах одиночного поиска, но показала падение в задачах множественного поиска из-за переобучения. Исследователи отмечают, что более крупные модели, такие как Qwen-1.5-72B-vLLM, в целом лучше справляются с сложными задачами логического рассуждения.
В заключение, NeedleBench представляет собой новую методику оценки возможностей долгоконтекстных LLMs, предлагая всестороннюю оценку способностей моделей обрабатывать сложные задачи поиска и рассуждения в длинных текстах. Эти результаты подчеркивают необходимость дальнейших улучшений в области LLMs для расширения их применимости в реальных сценариях с долгим контекстом.

























