«`html
ProgressGym: A Machine Learning Framework for Dynamic Ethical Alignment in Frontier AI Systems
Системы искусственного интеллекта (ИИ), включая LLMs, все больше формируют убеждения и ценности людей, выступая в качестве персональных помощников, образователей и авторов. Однако эти системы, обученные на огромных объемах человеческих данных, часто отражают и распространяют существующие общественные предубеждения. Это явление, известное как «захват ценностей», может закреплять ошибочные моральные убеждения и практики на общественном уровне, что потенциально усиливает проблематичное поведение, такое как бездействие по климату и дискриминация. Текущие методы выравнивания ИИ, такие как обучение с подкреплением на основе обратной связи от людей, должны быть пересмотрены, чтобы предотвратить это. ИИ-системы должны включать механизмы, эмулирующие моральный прогресс, чтобы решить проблему захвата ценностей и способствовать постоянному этическому развитию.
Прогрессное выравнивание в ИИ
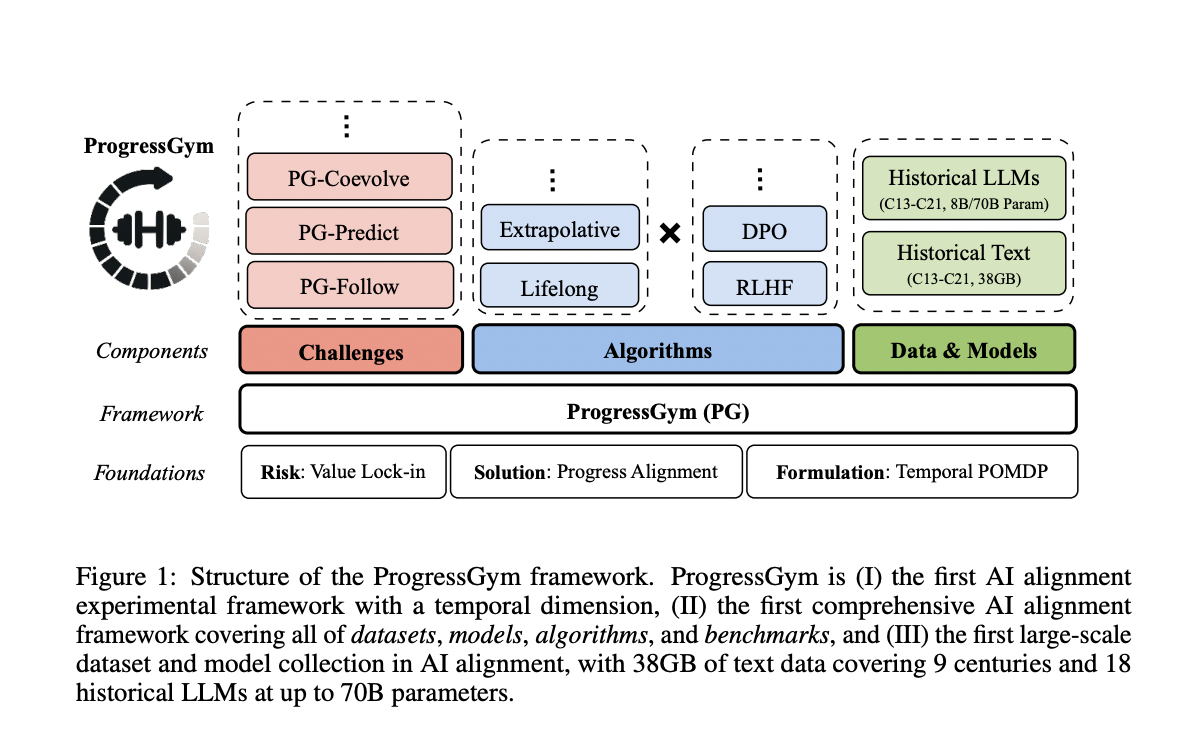
Исследователи из Пекинского университета и Корнеллского университета представляют «прогрессное выравнивание» в качестве решения для смягчения захвата ценностей в системах ИИ. Они представляют ProgressGym — инновационную платформу, использующую девять веков исторических текстов и 18 исторических LLMs для изучения и эмуляции морального прогресса человека. ProgressGym фокусируется на трех основных задачах: отслеживание эволюции ценностей, прогнозирование будущих моральных изменений и регулирование обратной связи между ценностями человека и ИИ. Платформа преобразует эти задачи в измеримые показатели и включает базовые алгоритмы для прогрессного выравнивания. ProgressGym нацелен на постоянное этическое развитие в ИИ путем учета временного аспекта выравнивания.
Исследования по выравниванию ИИ все больше фокусируются на обеспечение соответствия систем, особенно LLMs, предпочтениям человека, от поверхностных тонов до глубоких ценностей, таких как справедливость и мораль. Традиционные методы, такие как надзорная настройка и обучение с подкреплением на основе обратной связи от людей, часто опираются на статические предпочтения, что может усиливать предубеждения. Недавние подходы, включая Dynamic Reward MDP и On-the-fly Preference Optimization, учитывают изменяющиеся предпочтения, но требуют единой платформы. Прогрессное выравнивание предлагает эмуляцию морального прогресса человека в ИИ для соответствия изменяющимся ценностям. Этот подход направлен на смягчение эпистемологических вредов LLMs, таких как дезинформация, и на поощрение непрерывного этического развития, предлагая смесь технических и общественных решений.
Прогрессное выравнивание стремится моделировать и способствовать моральному прогрессу в системах ИИ. Оно формулируется как временная POMDP, где ИИ взаимодействует с эволюционирующими ценностями человека, и успех измеряется соответствием этим ценностям. Платформа ProgressGym поддерживает это, предоставляя обширные исторические текстовые данные и модели с XIII по XXI век. Эта платформа включает задачи, такие как отслеживание, прогнозирование и совместная эволюция с человеческими ценностями. Обширный набор данных и различные алгоритмы ProgressGym позволяют тестировать и разрабатывать методы выравнивания, учитывая эволюционный характер человеческой морали и роль ИИ.
ProgressGym предлагает унифицированную платформу для реализации вызовов прогрессного выравнивания, представляя их как временные POMDP. Каждая задача выравнивает поведение ИИ с эволюционирующими ценностями человека за девять веков. Платформа использует стандартизированное представление состояний человеческих ценностей, действий ИИ в диалогах и наблюдений из ответов человека. Среди вызовов PG-Follow, который обеспечивает соответствие ИИ текущим ценностям; PG-Predict, который тестирует способность ИИ предвидеть будущие ценности; и PG-Coevolve, который исследует взаимное влияние между ИИ и человеческими ценностями. Эти бенчмарки помогают измерить соответствие ИИ историческому и моральному прогрессу и предвидеть будущие изменения.
В рамках платформы ProgressGym алгоритмы выравнивания на протяжении жизни и экстраполяционные алгоритмы оцениваются как базовые для прогрессного выравнивания. Алгоритмы на протяжении жизни непрерывно применяют классические методы выравнивания, либо итеративно, либо независимо. Экстраполяционные алгоритмы предсказывают будущие ценности человека и выравнивают модели ИИ соответственно, используя операторы обратной разности для расширения временных предпочтений человека. Экспериментальные результаты по трем основным задачам — PG-Follow, PG-Predict и PG-Coevolve — показывают, что алгоритмы на протяжении жизни хорошо справляются, но экстраполяционные методы часто превосходят их с более высоким порядком экстраполяции. Эти результаты свидетельствуют о том, что прогностическое моделирование имеет ключевое значение для эффективного выравнивания ИИ с эволюционирующими ценностями человека во времени.
«`

























