Trust-Align: Фреймворк для повышения доверия к большим языковым моделям
Большие языковые модели (LLM) привлекли значительное внимание благодаря их потенциалу улучшить различные приложения искусственного интеллекта, особенно в области обработки естественного языка. Интегрированные в такие фреймворки, как Retrieval-Augmented Generation (RAG), эти модели направлены на улучшение выводов систем искусственного интеллекта, извлекая информацию из внешних документов, а не полагаясь исключительно на свою внутреннюю базу знаний. Этот подход критичен для обеспечения фактической точности контента, создаваемого искусственным интеллектом, что является постоянной проблемой для моделей, не привязанных к внешним источникам.
Проблема и ее решение
Одной из ключевых проблем в этой области является возникновение галлюцинаций в LLM, когда модели генерируют кажущуюся правдоподобной, но фактически неверную информацию. Это особенно проблематично в задачах, требующих высокой точности, таких как ответы на фактические вопросы или помощь в юридической и образовательной сферах. Многие передовые LLM сильно полагаются на параметрическую информацию, полученную в процессе обучения, что делает их непригодными для задач, в которых ответы должны строго исходить из конкретных документов. Для решения этой проблемы необходимо внедрение новых методов для оценки и улучшения надежности этих моделей.
Традиционные методы сосредотачиваются на оценке конечных результатов LLM в рамках фреймворка RAG, но мало кто исследует внутреннюю надежность самих моделей. В настоящее время подходы, такие как методы подсказок, направлены на согласование ответов моделей с информацией из документов. Однако эти методы часто оказываются неэффективными, либо не способны адаптировать модели, либо приводят к чрезмерно чувствительным выводам, которые реагируют некорректно. Исследователи выявили необходимость новой метрики для измерения производительности LLM и обеспечения того, чтобы модели предоставляли обоснованные, достоверные ответы, основанные исключительно на извлеченных документах.
Применение и результаты
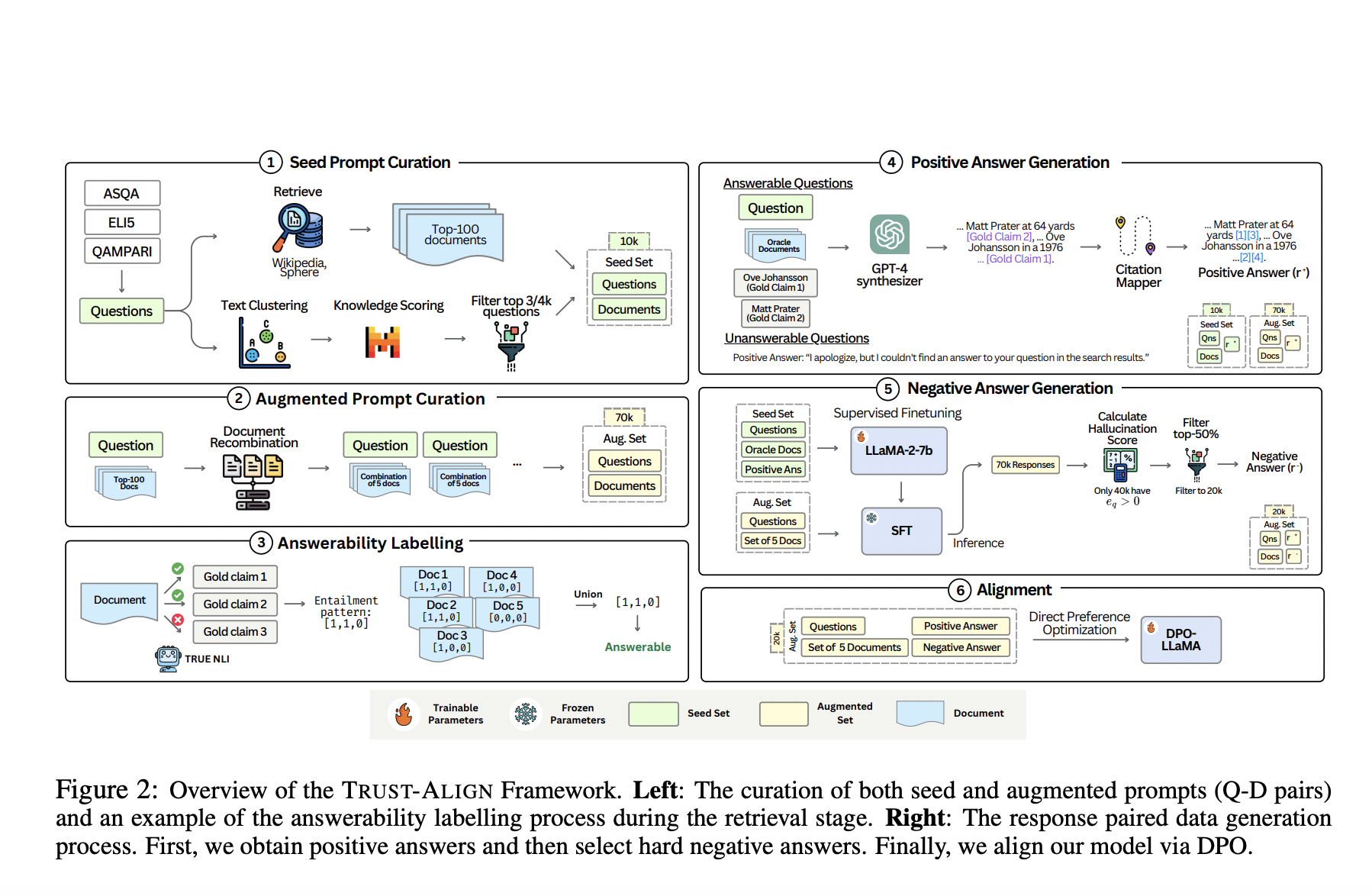
Исследователи из Университета технологий и дизайна Сингапура, совместно с Национальными лабораториями DSO, представили новый фреймворк под названием «TRUST-ALIGN». Этот метод фокусируется на повышении надежности LLM в задачах RAG путем выравнивания их выводов для предоставления более точных, подтвержденных документами ответов. Исследователи также разработали новую метрику оценки, TRUST-SCORE, которая оценивает модели по нескольким измерениям, таким как их способность определить, можно ли ответить на вопрос с использованием предоставленных документов, и их точность в цитировании соответствующих источников.
TRUST-ALIGN работает путем настройки LLM с использованием набора данных, содержащего 19 000 пар вопрос-документ, каждая помеченная предпочтительными и непредпочтительными ответами. Этот набор данных был создан путем синтеза естественных ответов от LLM, таких как GPT-4, и отрицательных ответов, выведенных из общих галлюцинаций. Основное преимущество этого метода заключается в его способности напрямую оптимизировать поведение LLM в направлении предоставления обоснованных отказов, когда это необходимо, обеспечивая, что модели отвечают на вопросы только при наличии достаточной информации. Он улучшает точность цитирования моделей, направляя их на ссылку на наиболее релевантные части документов, тем самым предотвращая чрезмерное цитирование или неправильное приписывание.
В целом, внедрение TRUST-ALIGN показало существенные улучшения на нескольких эталонных наборах данных. Например, при оценке на наборе данных ASQA, LLaMA-3-8b, выровненный с TRUST-ALIGN, достиг увеличения TRUST-SCORE на 10,73%, превзойдя модели, такие как GPT-4 и Claude-3.5 Sonnet. На наборе данных QAMPARI метод превзошел базовые модели на 29,24%, в то время как на наборе данных ELI5 показано увеличение производительности на 14,88%. Эти цифры демонстрируют эффективность фреймворка TRUST-ALIGN в генерации более точных и надежных ответов по сравнению с другими методами.

























