«`html
Видеоописание становится все более важным для понимания контента, поиска и обучения моделей на основе видео. Однако создание точных, подробных и описательных описаний видео представляет собой сложную задачу в областях компьютерного зрения и обработки естественного языка. Ряд ключевых препятствий затрудняют прогресс в этой области. Одним из примеров является недостаток высококачественных данных, так как данные из интернета часто неточны, а большие наборы данных очень дороги. Кроме того, видеоописание по своей природе более сложно, чем описание изображений из-за временных корреляций и движения камеры. Отсутствие установленных стандартов и критическая необходимость в правильности в приложениях, связанных с безопасностью, делают этот вызов более сложным в этой области.
Недавние достижения в области моделей визуального языка улучшили описание изображений, однако эти модели сталкиваются с трудностями в описании видео из-за временных сложностей. Были разработаны специальные модели для видео, такие как PLLaVa, Video-llava и Video-LLama, чтобы решить эту проблему. Их методы включают параметро-бесплатное пулингирование, совместное обучение изображений и видео, а также обработку звука. Исследователи также исследовали использование больших языковых моделей (LLM) для задач суммаризации, как показали LLaDA и метод переопределения OpenAI. Несмотря на эти достижения, в этой области необходимы установленные стандарты и критическая необходимость в точности в приложениях, связанных с безопасностью.
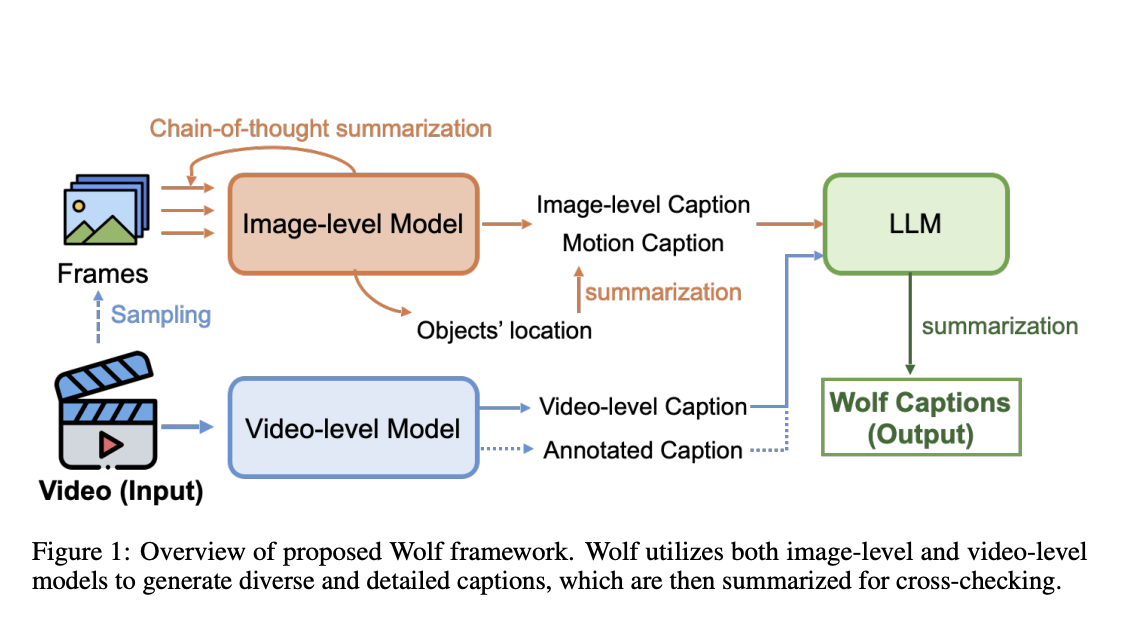
Исследователи из NVIDIA, UC Berkeley, MIT, UT Austin, University of Toronto и Stanford University предложили Wolf, WOrLd-фреймворк для точного видеоописания. Wolf использует подход смешанных экспертов, используя как модели визуального языка для изображений, так и видео, чтобы захватить различные уровни информации и эффективно суммировать. Фреймворк разработан для улучшения понимания видео, авто-маркировки и описания. Исследователи представили CapScore, метрику на основе LLM, которая оценивает сходство и качество созданных описаний по сравнению с эталоном. Wolf превосходит текущие передовые методы и коммерческие решения, значительно улучшая CapScore в сложных видео с вождением.
Оценка Wolf использует четыре набора данных: 500 интерактивных видео Nuscences, 4 785 обычных видео Nuscences, 473 общих видео и 100 видео с роботами. Предложенная метрика CapScore оценивает сходство описания с эталоном. Предложенный метод сравнивается с передовыми методами, включая CogAgent, GPT-4V, VILA-1.5 и Gemini-Pro-1.5. Методы на уровне изображения, такие как CogAgent и GPT-4V, обрабатывают последовательные кадры, в то время как видео-ориентированные методы, такие как VILA-1.5 и Gemini-Pro-1.5, обрабатывают полные видео. Используется единый запрос для всех моделей, с акцентом на расширение визуальных и повествовательных элементов, особенно поведения объектов.
Результаты показывают, что Wolf превосходит передовые подходы в видеоописании. В то время как GPT-4V лучше в распознавании сцен, у него возникают трудности с временной информацией. Gemini-Pro-1.5 захватывает некоторый контекст видео, но уступает в деталях описания движения. В отличие от этого, Wolf эффективно захватывает контекст сцены и детальное описание движения, такое как движение транспортных средств в разных направлениях и реакция на светофоры. Количественно Wolf превосходит текущие методы, такие как VILA1.5, CogAgent, Gemini-Pro-1.5 и GPT-4V. В сложных видео с вождением Wolf улучшает CapScore на 55,6% по качеству и на 77,4% по сходству по сравнению с GPT-4V. Эти результаты подчеркивают способность Wolf предоставлять более полные и точные описания видео.
В заключение, исследователи представили Wolf, WOrLd-фреймворк для точного видеоописания. Wolf представляет собой значительный прогресс в автоматизированном видеоописании, объединяя модели описания и техники суммаризации для создания подробных и правильных описаний. Этот подход позволяет понимать видео с различных точек зрения, особенно преуспевая в сложных сценариях, таких как видео с множественными ракурсами вождения. Исследователи создали таблицу лидеров для поощрения конкуренции и инноваций в технологии видеоописания. Они также планируют создать обширную библиотеку с разнообразными типами видео с высококачественными описаниями, региональной информацией, такой как 2D или 3D ограничивающие рамки и данные о глубине, а также деталями движения нескольких объектов.
«`

























