FastGen: снижение затрат на память GPU без ущерба качеству LLM
Авторегрессивные языковые модели (ALM) доказали свою способность в машинном переводе, генерации текста и т. д. Однако эти модели представляют вызовы, включая вычислительную сложность и использование памяти GPU. Несмотря на большой успех в различных приложениях, существует срочная необходимость найти экономичный способ обслуживания этих моделей. Более того, генеративное вывод больших языковых моделей (LLM) использует механизм кэширования KV для улучшения скорости генерации. Тем не менее, увеличение размера модели и длины генерации приводит к увеличению использования памяти кэша KV. Когда использование памяти превышает емкость GPU, генеративное вывод LLM прибегает к выгрузке.
Практические решения и ценность:
Множество работ было проведено для повышения эффективности модели для LLM, например, одним из таких методов является пропуск нескольких токенов в определенный момент времени. Недавно была предложена техника, добавляющая задачу выбора токена к исходной модели BERT, которая учится выбирать важные токены и обнаруживать неважные токены для обрезки с использованием разработанного обучаемого порога. Однако эти модели применяются только к неавторегрессивным моделям и требуют дополнительной фазы повторного обучения, что делает их менее подходящими для авторегрессивных LLM, таких как ChatGPT и Llama. Важно рассмотреть потенциал обрезки токенов в кэше KV авторегрессивных LLM для заполнения этой пробела.
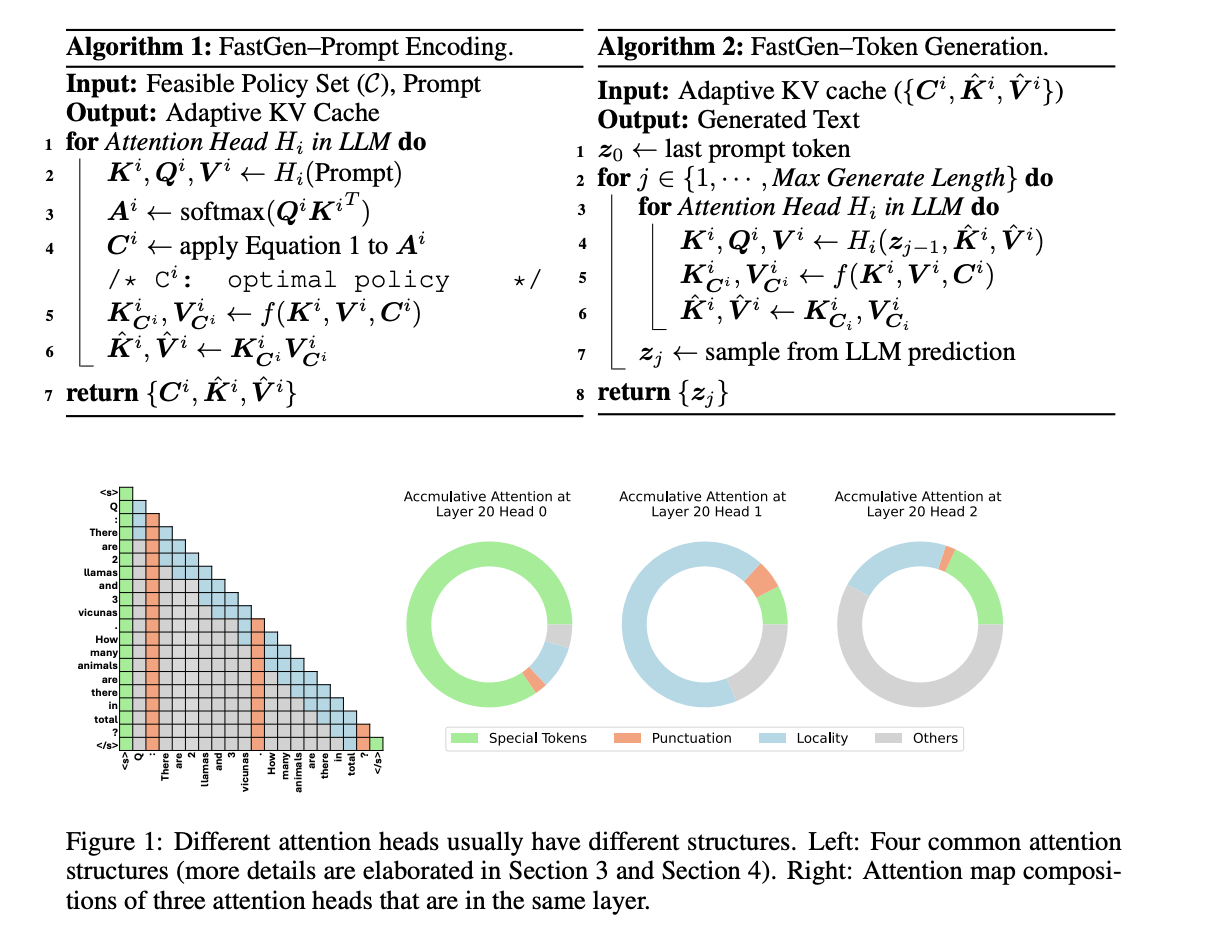
Исследователи из Университета Иллинойса в Урбане-Шампейне и Microsoft предложили FastGen, высокоэффективную технику для повышения эффективности вывода LLM без потери видимого качества, используя профилирование легкой модели и адаптивное кэширование ключ-значение. FastGen удаляет контексты дальнего диапазона на головах внимания с помощью построения кэша KV адаптивным образом. Кроме того, он использует легкое профилирование внимания, которое используется для направления построения адаптивного кэша KV без ресурсоемкого тонкой настройки или повторного обучения. FastGen способен снизить использование памяти GPU с незначительной потерей качества генерации.
Результаты исследования:
Адаптивное сжатие кэша KV, предложенное исследователями, снижает объем памяти генеративного вывода для LLM. Для моделей 30B FastGen превосходит все неадаптивные методы сжатия KV и достигает более высокого коэффициента сокращения кэша KV с увеличением размера модели, сохраняя при этом качество модели неизменным. Например, FastGen получает коэффициент обрезки 44,9% на Llama 1-65B по сравнению с коэффициентом обрезки 16,9% на Llama 1-7B, достигая победного коэффициента 45%. Кроме того, был проведен анализ чувствительности FastGen путем выбора различных гиперпараметров. Поскольку модель поддерживает победный коэффициент 45%, исследование не показывает видимого влияния на качество генерации после изменения гиперпараметра.
В заключение, исследователи из Университета Иллинойса в Урбане-Шампейне и Microsoft предложили FastGen, новую технику для повышения эффективности вывода LLM без потери видимого качества, используя профилирование легкой модели и адаптивное кэширование ключ-значение. Также адаптивное сжатие кэша KV, предложенное исследователями, используется для снижения объема памяти генеративного вывода для LLM. Будущая работа включает интеграцию FastGen с другими методами сжатия модели, например, квантизацией и дистилляцией, групповым запросом внимания и т. д.









