МаVEn: эффективная многоуровневая гибридная система визуального кодирования для многомодальных крупных языковых моделей (MLLMs)
Существующие многомодальные крупные языковые модели (MLLMs) сосредоточены на индивидуальной интерпретации изображений, что ограничивает их возможность решать задачи, включающие множество изображений. Для эффективной работы с такими задачами необходимо, чтобы модели понимали и интегрировали информацию сразу по нескольким изображениям.
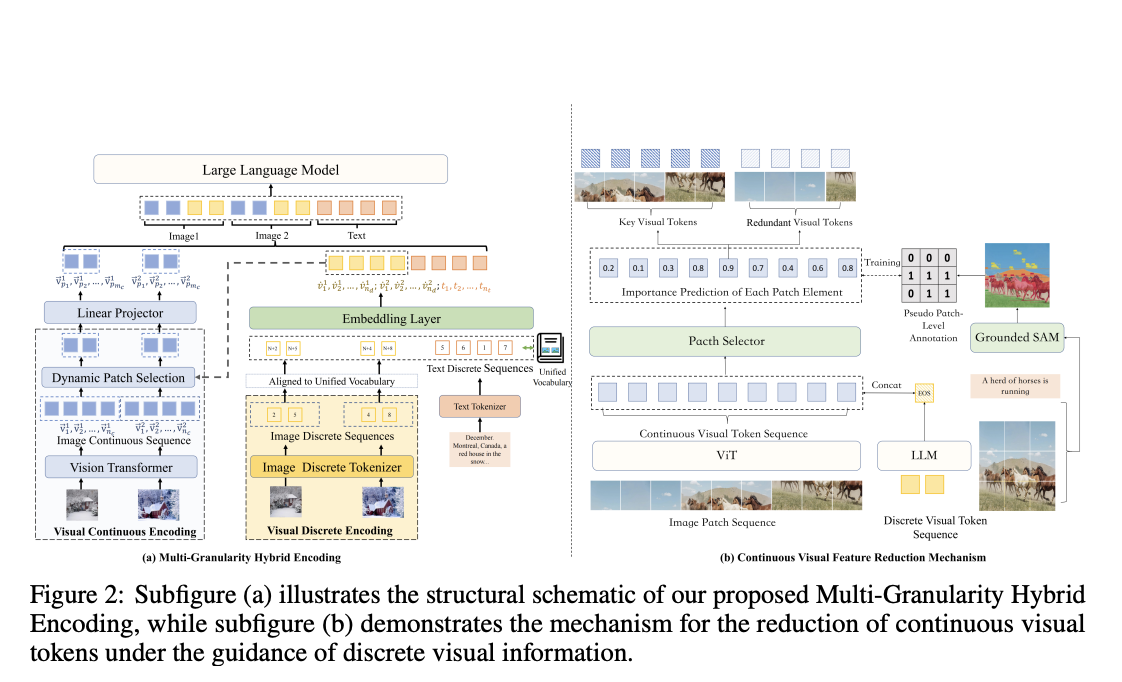
В недавнем исследовании команда ученых представила МаВЕn, многоуровневую систему визуального кодирования, созданную для улучшения производительности MLLMs в задачах требующих рассуждения по нескольким изображениям. Эта уникальная система сочетает два различных вида визуальных представлений, чтобы преодолеть ограничения, с которыми сталкиваются существующие модели.
Основные особенности MaVEn:
- Дискретные визуальные символьные последовательности: Извлекают семантические концепции изображений. MaVEn абстрагирует визуальную информацию в дискретные символы, облегчая моделирование и интеграцию этой информации с текстовыми данными.
- Последовательности для непрерывного представления: Используются для воссоздания мелких деталей изображений, сохраняя специфические визуальные детали. Это обеспечивает доступ модели к тонкой информации, необходимой для обоснованного толкования и логики.
MaVEn сочетает эти два подхода, улучшая способность модели к пониманию и обработке информации с нескольких изображений. Такая двойная система кодирования сохраняет эффективность модели в задачах, связанных с одним изображением, одновременно улучшая ее производительность в многокартинных сценариях.
Кроме того, MaVEn предлагает динамический метод снижения длинных последовательностей непрерывных признаков, что позволяет оптимизировать производительность модели и снизить вычислительную сложность без ущерба для качества визуальных данных.
Эксперименты показали, что MaVEn значительно улучшает производительность MLLM в сложных ситуациях, требующих рассуждения на многих изображениях, а также улучшает производительность моделей в задачах с одним изображением, что делает его универсальным решением для различных приложений визуальной обработки.
Основные преимущества исследования:
- Уникальная система, сочетающая непрерывные и дискретные визуальные представления, значительно улучшает способность MLLM к обработке сложной визуальной информации с нескольких изображений и рассуждениям по ним.
- Динамический механизм снижения длинных последовательностей визуальных аспектов позволяет оптимизировать процесс обработки нескольких изображений снижая вычислительную сложность без утраты точности.
- Метод успешно работает в различных сценариях рассуждения на нескольких изображениях, а также демонстрирует преимущества в стандартных задачах с одним изображением, что подтверждает его адаптивность и эффективность в различных приложениях визуальной обработки.
Представленное исследование демонстрирует значительные улучшения в производительности MLLM в сложных ситуациях, требующих рассуждения на нескольких изображениях. Это также показывает, как данная система улучшает производительность моделей в задачах с одним изображением, делая ее универсальным решением для различных приложений визуальной обработки.

























