Новый метод T-FREE: эффективное и масштабируемое кодирование текста в больших языковых моделях без токенизаторов
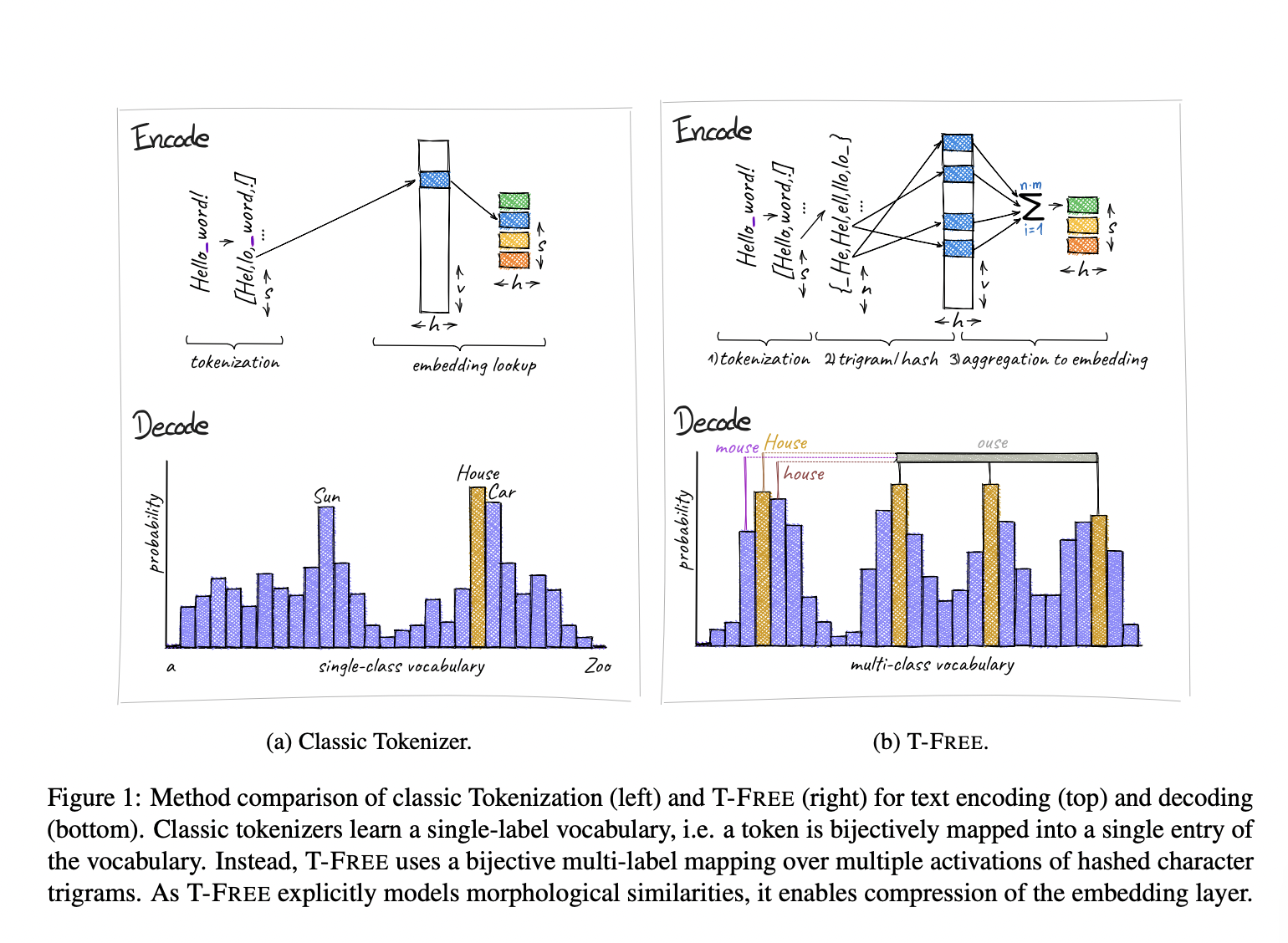
Метод T-FREE представляет собой инновационный подход к кодированию текста в больших языковых моделях без использования токенизаторов. Этот метод значительно уменьшает размер вложенных слоев и улучшает производительность на различных языках.
Практическое применение
Разработка T-FREE позволяет существенно улучшить результаты в переносе обучения между языками, что является особенно важным для недостаточно изученных языков. Модели, использующие T-FREE, продемонстрировали более высокие результаты в тестах, что подтверждает их эффективность и эффективность при работе с разнообразными языками и задачами.
Подробные оценки показали, что метод T-FREE может достичь конкурентоспособных результатов с существенно уменьшенным размером словаря, а их размер в 8 000 записей обеспечивает лучшую производительность. Этот подход также позволяет снизить количество параметров на 20%, используя 2,77 миллиарда параметров по сравнению с 3,11 миллиарда для традиционных методов.
Метод T-FREE значительно уменьшает вычислительные расходы, связанные с предварительной обработкой, обучением и выводом больших языковых моделей. Он также позволяет явно моделировать и управлять процессом декодирования во время вывода, что потенциально позволяет снизить галлюцинации и вносить динамические корректировки в доступный словарь.
Таким образом, метод T-FREE значительно преодолевает ограничения текущих методов токенизации, предлагая более эффективный и эффективный метод кодирования текста в больших языковых моделях.

























