Эффективное развертывание масштабных моделей трансформеров: стратегии масштабируемого и низколатентного вывода
Разработка больших моделей трансформеров в размере более 100 миллиардов параметров привела к революционным результатам в обработке естественного языка. Однако эффективное развертывание подобных моделей представляет определенные вызовы из-за последовательной природы генеративного вывода. Нам удалось выделить ключевые инженерные принципы для эффективного обслуживания моделей трансформеров в различных условиях производства, обеспечивая масштабируемость и низкую латентность вывода.
Практические решения и ценность
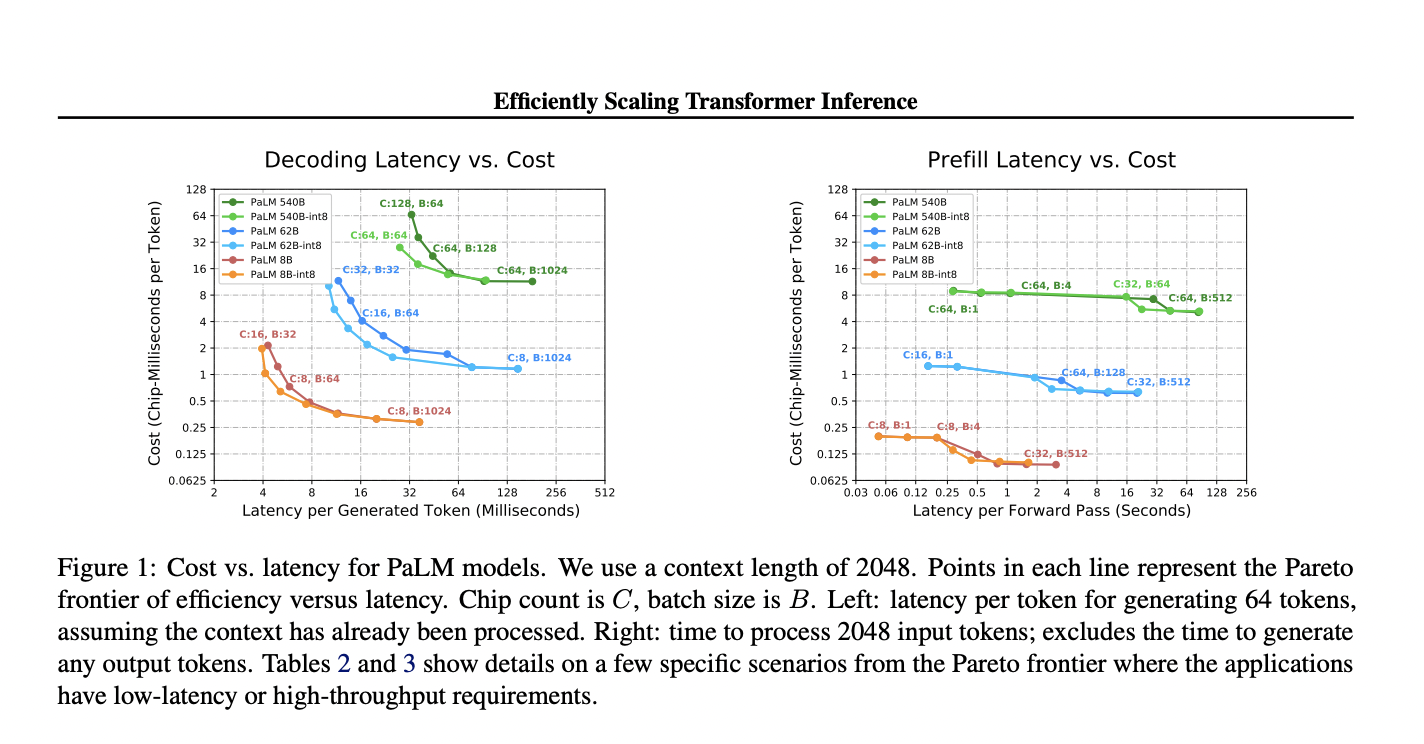
Исследования Google показали, что оптимизация многомерных методик разделения для чипов TPU v4 при высоких целях латентности и длинных последовательностях позволила достичь превосходной латентности и улучшенной использования FLOPS модели для моделей с 500 миллиардами параметров, превзойдя результаты бенчмарков FasterTransformer. Использование множественных запросов внимания позволило увеличить длину контекста до 32 раз больше. Разработанная модель PaLM 540B достигла латентности в 29 мс на токен с квантованием int8 и 76% использования FLOPS модели, что подтверждает практическое применение в чат-ботах и высокопроизводительных офлайн-вычислениях.
Как показывает исследование, масштабирование размеров моделей улучшает их возможности, но также увеличивает латентность, производительность и затраты на вывод в MFU. Для повышения эффективности вывода предлагается ряд подходов.
Мы можем помочь вашей компании осуществить переход к использованию искусственного интеллекта. Напишите нам, чтобы получить советы по внедрению ИИ и попробовать ИИ ассистент в продажах от Flycode.ru.

























