“`html
Loss-Free Balancing: Новая стратегия для достижения оптимального распределения нагрузки в моделях смеси экспертов с параметрами от 1 млрд до 3 млрд, улучшающая производительность на уровне от 100 млрд до 200 млрд токенов
Модели смеси экспертов (MoE) стали ключевым инновационным решением в машинном обучении, особенно в масштабировании больших языковых моделей (LLM). Они разработаны для управления растущими вычислительными требованиями обработки обширных данных. За счет использования нескольких специализированных экспертов в одной модели архитектуры MoE можно эффективно направлять конкретные задачи к наиболее подходящему эксперту, оптимизируя производительность. Этот подход оказался полезным в обработке естественного языка (NLP), где одновременное выполнение разнообразных и сложных задач является важным для достижения точности и эффективности.
Проблема неравномерной нагрузки
Одной из наиболее существенных проблем, с которой сталкиваются модели MoE, является неравномерное распределение нагрузки среди экспертов. Некоторые эксперты могут перегружаться задачами в таких моделях, в то время как другие могут быть менее задействованы, что приводит к неэффективности. Это неравновесие может привести к сбою маршрутизации, когда модель повторно выбирает несколько экспертов, что затрудняет общий процесс обучения. Кроме того, неравномерное распределение задач увеличивает вычислительную нагрузку, поскольку модели требуется помощь в эффективном управлении нагрузкой. Решение этой проблемы критично, поскольку оно напрямую влияет на способность модели работать оптимально, особенно при масштабировании для обработки больших наборов данных и сложных задач обработки языка.
Решение: Loss-Free Balancing
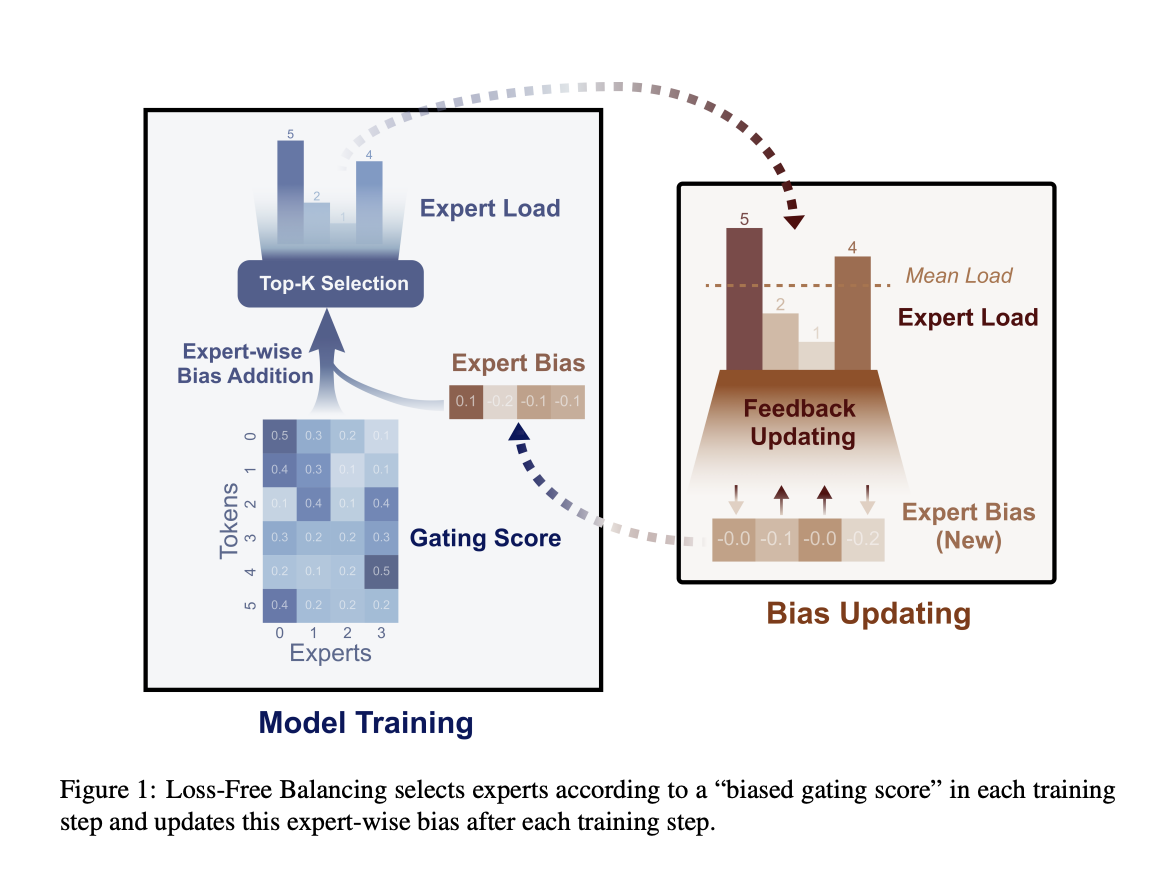
Компания DeepSeek-AI и исследователи Университета Пекина разработали новый подход под названием Loss-Free Balancing. Этот метод устраняет необходимость в дополнительных функциях потерь путем динамической настройки маршрутизации задач к экспертам на основе их текущей нагрузки. В отличие от предыдущих методов, которые вносили нежелательные градиенты, Loss-Free Balancing сосредотачивается на поддержании равномерного распределения задач без вмешательства в основные цели обучения модели. Этот подход позволяет модели работать более эффективно, обеспечивая эффективное использование всех экспертов без ущерба производительности.
Метод Loss-Free Balancing осуществляет динамическую настройку смещения для каждого эксперта перед принятием решений о маршрутизации. Эти смещения непрерывно обновляются на основе недавней нагрузки, наблюдаемой для каждого эксперта. Например, если эксперт был интенсивно задействован на последних этапах обучения, его смещение уменьшается для снижения нагрузки. Напротив, если эксперт был мало задействован, его смещение увеличивается, стимулируя модель маршрутизировать больше задач к нему. Этот итеративный процесс обеспечивает постоянное равновесие функций между всеми экспертами, повышая эффективность и производительность модели.
Эмпирические результаты
Метод Loss-Free Balancing значительно улучшил результаты по сравнению с традиционными стратегиями, основанными на дополнительных функциях потерь. В экспериментах, проведенных на моделях MoE с 1 миллиардом (1B) параметров, обученных на 100 миллиардах (100B) токенов, и более крупных моделях с 3 миллиардами (3B) параметров, обученных на 200 миллиардах (200B) токенов, исследователи обнаружили заметные улучшения как в равномерности нагрузки, так и в общей производительности модели. Например, показатель проверочной перплексии, ключевой показатель производительности модели, снизился до 9.50 в модели с 1B параметров и до 7.92 в модели с 3B параметров при использовании Loss-Free Balancing. Метод достиг максимального нарушения (MaxVio) глобального равновесия нагрузки всего 0.04, что значительно лучше результатов, полученных с помощью методов с контролируемыми дополнительными потерями. Эти результаты подчеркивают эффективность подхода Loss-Free Balancing в поддержании равномерного распределения нагрузки при улучшении возможностей модели обработки языка.
Исследовательская группа также исследовала различные конфигурации и настройки для дальнейшей оптимизации метода Loss-Free Balancing. Они экспериментировали с различными скоростями обновления смещения и правилами для определения наиболее эффективного подхода. Например, скорость обновления 0.001 обеспечила хороший баланс между скоростью сходимости и стабильностью нагрузки. При изучении альтернативных методов, таких как мультипликативные смещения, исследователи пришли к выводу, что аддитивные смещения обеспечивают более высокую производительность и равномерное распределение нагрузки. Эти усовершенствования подчеркивают адаптивность метода и его потенциал для дальнейшей оптимизации в будущих приложениях.
В заключение, метод Loss-Free Balancing обеспечивает более эффективное и эффективное обучение масштабных языковых моделей путем решения проблемы неравномерной нагрузки без введения нежелательных градиентов. Эмпирические результаты, включая снижение проверочной перплексии и улучшение метрик равномерности нагрузки, демонстрируют потенциал этого подхода для улучшения производительности моделей MoE в различных областях применения.
“`
























