Исследование стратегий параметрически-эффективного донастройки для больших языковых моделей
Большие языковые модели (LLM) представляют собой революционный скачок во многих областях применения, обеспечивая впечатляющие достижения в различных задачах. Однако их огромный размер вызывает значительные вычислительные затраты. С миллиардами параметров эти модели требуют обширных вычислительных ресурсов для работы. Адаптация их к конкретным задачам становится особенно сложной из-за их огромного масштаба и вычислительных требований, особенно на аппаратных платформах, ограниченных вычислительными возможностями.
Применение LLM
Предыдущие исследования показали, что LLM обладают значительной обобщающей способностью, позволяющей им применять полученные знания к новым задачам, не встречавшимся во время обучения, явление, известное как обучение с нуля. Однако для оптимизации производительности LLM на надежных пользовательских наборах данных и задачах остается важным их донастройка. Одной из широко применяемых стратегий донастройки является регулирование подмножества параметров LLM, оставляя остальные без изменений, называемое параметрически-эффективной донастройкой (PEFT). Эта техника выборочно изменяет небольшую часть параметров, оставляя большинство нетронутыми. Применение PEFT распространяется за пределы обработки естественного языка (NLP) на компьютерное зрение (CV), привлекая интерес к донастройке больших параметрических моделей зрения, таких как Vision Transformers (ViT) и моделей диффузии, а также междисциплинарных моделей зрения-языка.
Исследование и категоризация алгоритмов PEFT
Исследователи из Норт-Вестернского университета, Университета Калифорнии, Университета штата Аризона и Нью-Йоркского университета представляют этот обзор, тщательно исследующий разнообразные алгоритмы PEFT и оценивающий их производительность и вычислительные требования. Он также предоставляет обзор разработанных приложений с использованием различных методов PEFT и обсуждает общие стратегии, применяемые для снижения вычислительных расходов, связанных с PEFT. Помимо алгоритмических соображений, обзор углубляется в проектирование систем реального мира для изучения затрат на реализацию различных алгоритмов PEFT. Как бесценный ресурс, этот обзор оснащает исследователей пониманием алгоритмов PEFT и их системных реализаций, предлагая подробные анализы последних прогрессов и практических применений.
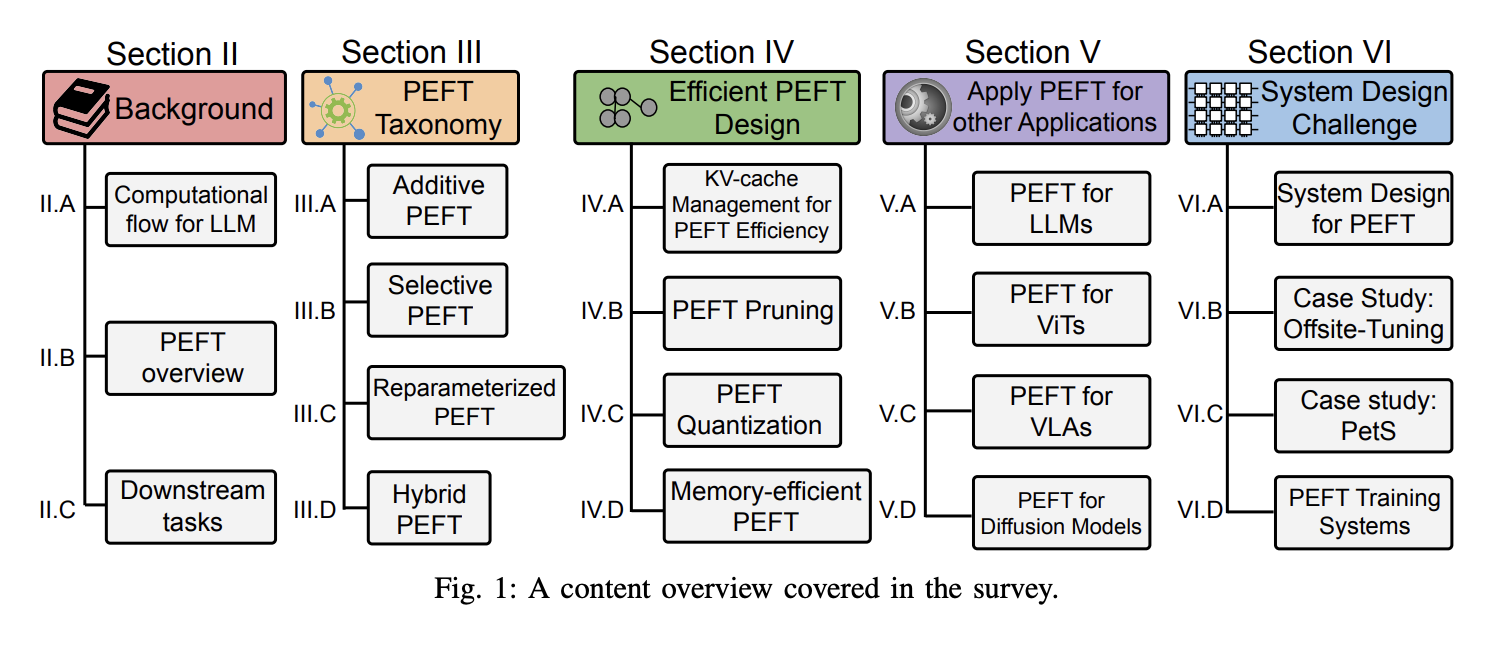
Категоризация алгоритмов PEFT
Исследователи категоризировали алгоритмы PEFT на аддитивные, выборочные, репараметризованные и гибридные донастройки на основе их операций. Основные алгоритмы аддитивной донастройки включают адаптеры, мягкие подсказки и другие, отличающиеся дополнительными настраиваемыми модулями или параметрами, которые они используют. Выборочная донастройка, напротив, включает выбор небольшого подмножества параметров из основной модели, делая только эти параметры настраиваемыми, оставляя большинство нетронутыми во время донастройки задачи. Выборочная донастройка категоризируется на основе группировки выбранных параметров: Неструктурное маскирование и Структурное маскирование. Репараметризация включает преобразование параметров модели между двумя эквивалентными формами, вводя дополнительные настраиваемые параметры низкого ранга во время обучения, которые затем интегрируются с исходной моделью для вывода. Этот подход охватывает две основные стратегии: декомпозиция низкого ранга и производные LoRA. Гибридная донастройка исследует различные пространства проектирования методов PEFT и объединяет их преимущества.
Расходы на вычисления и память в LLM
Был установлен ряд параметров для изучения затрат на вычисления и избыточной памяти в LLM в качестве основы для последующего анализа. В LLM токены (слова) генерируются итеративно на основе предыдущего запроса (ввода) и ранее сгенерированной последовательности. Этот процесс продолжается до тех пор, пока модель не выведет токен завершения. Одной из общих стратегий для ускорения вывода в LLM является сохранение предыдущих ключей и значений в кеше KeyValue (KV-cache), что позволяет избежать их повторного вычисления для каждого нового токена.
Заключение
В заключение, этот обзор всесторонне исследует разнообразные алгоритмы PEFT, предоставляя понимание их производительности, приложений и затрат на реализацию. Путем категоризации методов PEFT и изучения вычислительных и памятных соображений это исследование предлагает бесценное руководство для исследователей, преодолевающих сложности донастройки больших моделей.

























