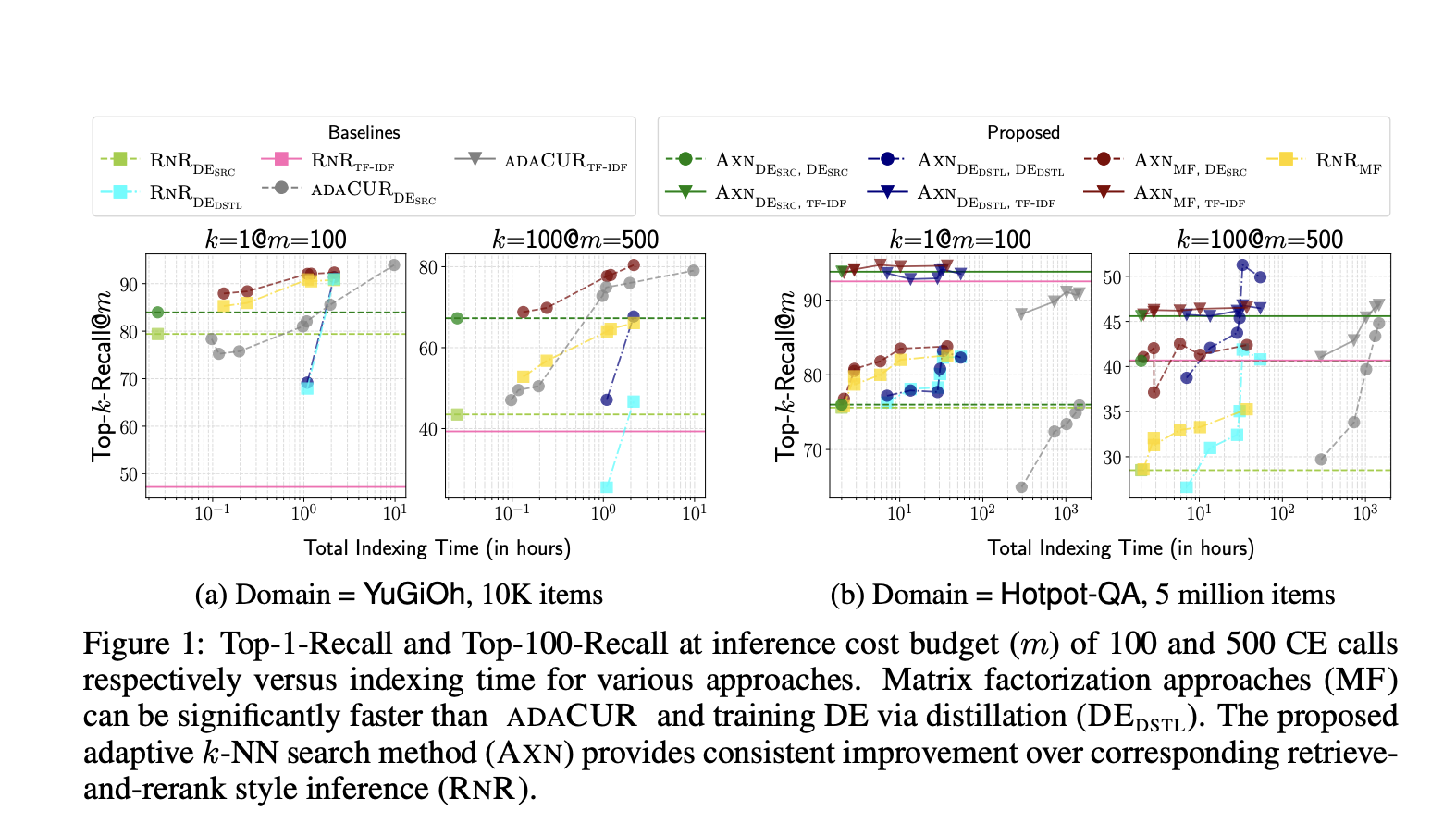
Эффективное вычисление скрытых запросов и представлений элементов для приближения CE-оценок
Кросс-энкодер (CE) модели оценивают сходство, одновременно кодируя пару запрос-элемент, превосходя dot-product с моделями на основе вложений при оценке релевантности запроса-элемента. Текущие методы выполняют поиск k-NN с CE, аппроксимируя CE-сходство с векторным пространством вложений, подходящим для двойных энкодеров (DE) или факторизации матрицы CUR. Однако методы на основе DE сталкиваются с проблемами низкой полноты из-за плохой обобщенности новых доменов и отделения тестового времени извлечения с DE от CE. Таким образом, методы на основе DE и CUR недостаточны для определенной настройки приложения в поиске k-NN.
Практические решения и ценность:
Метод оптимально вычисляет скрытые запросы и представления элементов для приближения CE-оценок и выполняет поиск k-NN с использованием аппроксимации CE-сходства. Проведены тщательные оценки методов и базовых линий на задачах, таких как поиск k-ближайших соседей для CE-моделей и последующие задачи. Эксперименты проводились на двух наборах данных, ZESHEL и BEIR, где для обоих использовались отдельные CE-модели, обученные на данных с маркировкой истинности.
Подробнее ознакомиться с исследованием.
Все права на это исследование принадлежат его авторам.
Не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.

























