«`html
Практические решения для улучшения производительности и эффективности долгих контекстуальных моделей языка
Метод MInference для ускорения обработки длинных последовательностей в моделях долгих контекстов
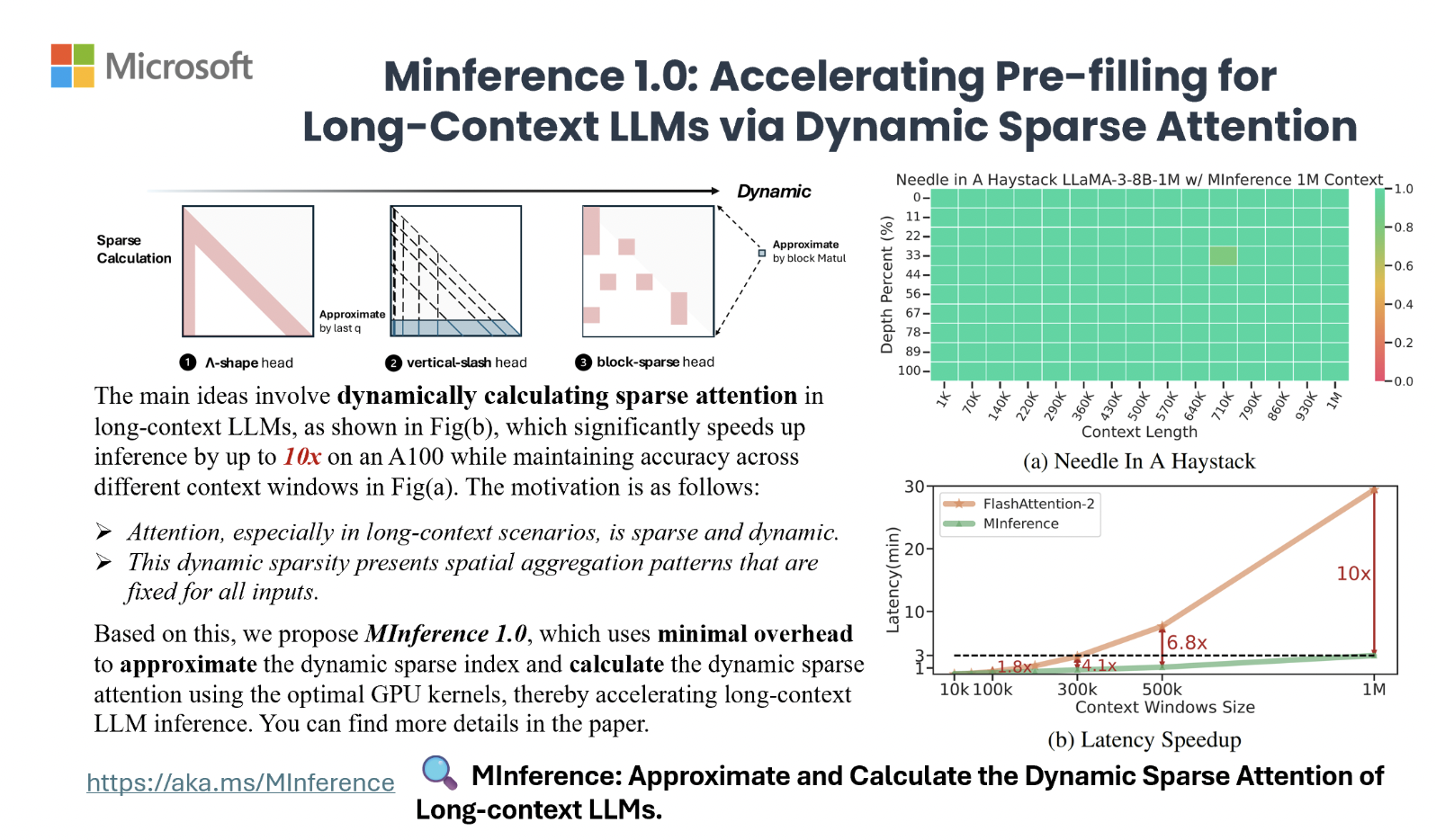
Метод MInference (Milliontokens Inference) был разработан исследователями из Microsoft Corporation и Университета Суррея для ускорения обработки длинных последовательностей в моделях долгих контекстов. Метод идентифицирует три различных образца внимания – A-shape, Vertical-Slash и Block-Sparse и оптимизирует разреженные вычисления для графических процессоров (GPU). Динамическое построение разреженных индексов для этих образцов в процессе вывода значительно снижает задержку, не меняя предварительное обучение или требуя доработки.
Эксперименты на различных моделях языка и бенчмарках показывают ускорение до 10 раз, сокращая этап предварительного заполнения с 30 минут до 3 минут на одном графическом процессоре A100 при сохранении точности.
Оптимизация разреженных вычислений и их применение
MInference использует динамическое разреженное внимание с конкретными пространственными образцами (A-shape, Vertical-Slash и Block-Sparse) для ускорения обработки длинных контекстов, снижая вычислительные затраты и поддерживая точность.
Метод также демонстрирует перспективы в мульти-модальных и кодировщик-декодировщик моделях языка, ускоряя этап предварительного заполнения и предоставляя значительное снижение задержки.
Практическая ценность MInference
Тестирование на бенчмарках, таких как InfiniteBench и RULER, показывает, что MInference поддерживает производительность длинных контекстов, обеспечивая ускорение до 10 раз и существенное снижение задержки на одном графическом процессоре A100 с 30 минут до 3 минут для последовательностей до 1 миллиона токенов.
Такие образцы также имеют потенциал для ускорения этапа предварительного заполнения в мульти-модальных и кодировщик-декодировщик моделях языка, что указывает на перспективные области применения приложений ускорения этапа предварительного заполнения.
«`

























