“`html
Новое в искусственном интеллекте (AI): HUSKY – универсальный открытый языковой агент для многократного логического рассуждения в различных областях
В последнее время разработаны языковые модели с большой глубиной дают ключ к созданию агентов способных решать сложные многошаговые задачи с использованием внешних инструментов. Текущие языковые агенты, работающие на закрытых моделях или моделях, специализированных на определенные задачи, часто обладают высокой стоимостью и проблемами задержки из-за зависимости от API. Открытые языковые модели узко ориентированы на ответы на многократные вопросы или требуют сложных процессов тренировки и вывода. Несмотря на вычислительные и фактические ограничения, языковые агенты представляют собой перспективный подход к методическому использованию внешних инструментов для решения сложных задач.
Результаты и Применение HUSKY
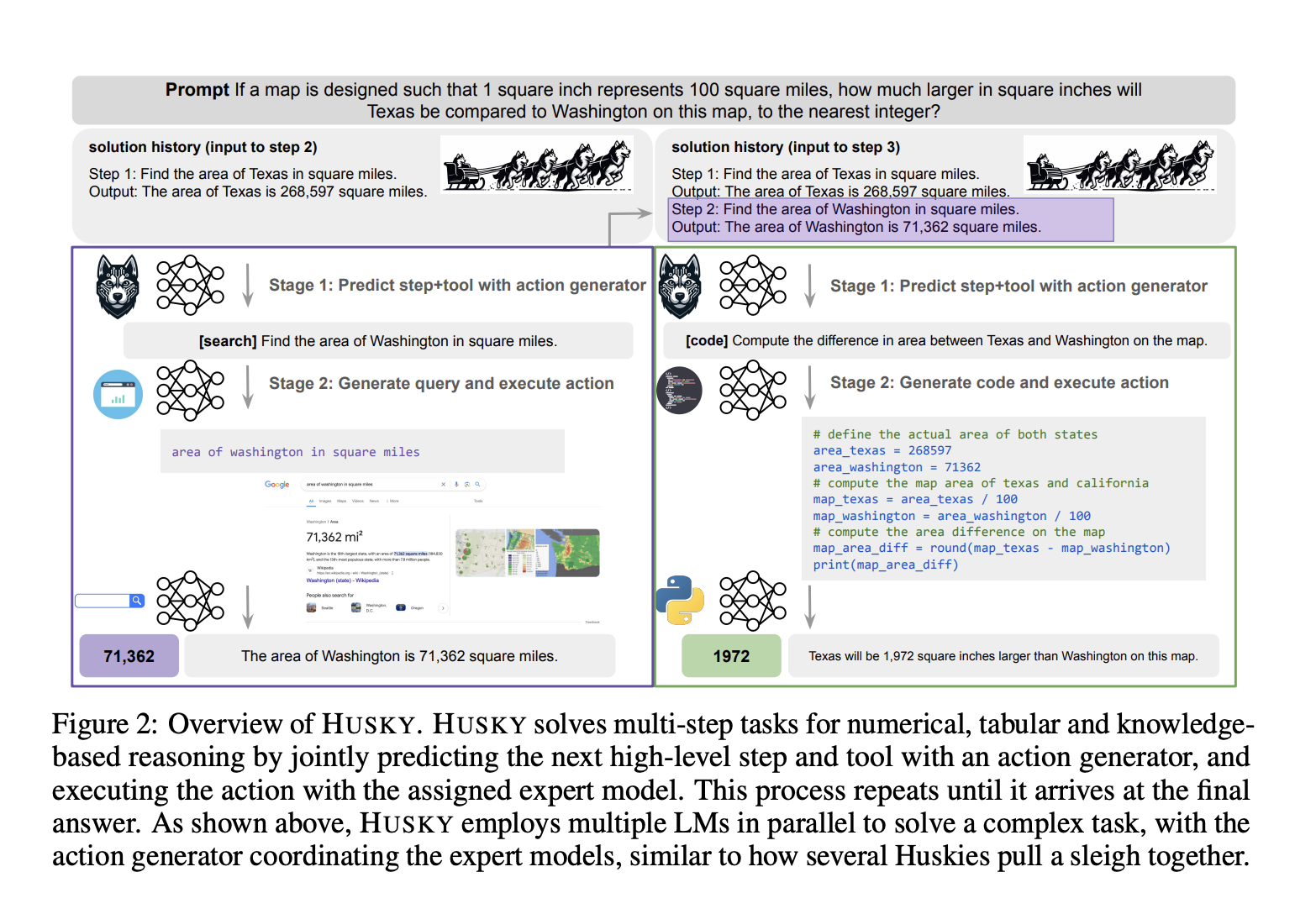
Ученые Университета Вашингтона, Meta AI и Института Аллена по AI представили HUSKY — универсального открытого языкового агента для решения разнообразных сложных задач, включая числовое, табличное и знаниевое рассуждение. HUSKY работает в двух ключевых этапах: создание следующего действия и его выполнение с использованием экспертных моделей. Агент использует унифицированное действие и интегрирует инструменты, такие как код, математика, поиск и логика общедоступного знания. Несмотря на использование меньших моделей 7B, экстенсивное тестирование показывает, что HUSKY превосходит более крупные, передовые модели на различных бенчмарках. Это продемонстрировало надежный и масштабируемый подход к решению многократных задач логического рассуждения эффективно.
Преимущества языковых агентов
Языковые агенты стали неотъемлемым элементом решения сложных задач путем использования языковых моделей для создания планов или выбора инструментов для конкретных шагов. Они обычно полагаются на либо закрытые, либо открытые модели. Более ранние агенты использовали закрытые модели для планирования и выполнения, которые, хотя иэффективны, облачены в высокие издержки и неэффективны из-за зависимости от API. Последние достижения сфокусированы на открытых моделях, сведенных из более крупных учительских моделей, предлагающих больший контроль и эффективность, но часто специализирующихся в узких областях. В отличие от них, HUSKY использует широкий унифицированный подход с простым процессом кураторства данных, используя инструменты для кодирования, математического рассуждения, поиска и логического рассуждения для эффективного решения различных задач.
Применение в различных областях
Как языковой агент, HUSKY разработан для решения сложных многократных задач логического рассуждения в различных областях посредством двухэтапного процесса: прогнозирование и выполнение действий. Он использует генератор действий для определения следующего шага и соответствующего инструмента, а затем экспертные модели для выполнения этих действий. Экспертные модели обрабатывают задачи, такие как генерация кода, выполнение математического рассуждения и формулировка поисковых запросов. HUSKY повторяет этот процесс до достижения окончательного решения. Обученный на синтетических данных, HUSKY сочетает гибкость и эффективность в различных областях. Он оценивается на наборах данных, требующих различных инструментов, включая HUSKYQA, новый набор данных, разработанный для тестирования способностей к числовому рассуждению и извлечению информации.
Результаты и Применение HUSKY в различных областях
В своей оценке HUSKY был проверен на разнообразных задачах, включающих числовое, табличное и знаниевое рассуждение, а также задачи смешанного использ. Используя наборы данных, такие как GSM-8K, MATH и FinQA для тренировки, HUSKY показывает стабильную производительность в решении невиденных задач, часто превосходя других агентов, таких как REACT, CHAMELEON, и закрытые модели, такие как GPT-4. Модель интегрирует инструменты и модули, настроенные для конкретных задач логического рассуждения, используя тонкие модели, такие как LLAMA и DeepSeekMath. Это обеспечивает точное, пошаговое решение проблем в разных областях, подчеркивая продвинутые способности HUSKY в многократном использовании инструментов и итеративном разложении задач.
Гибкость и масштабируемость HUSKY
В заключение, HUSKY — открытый языковой агент, разработанный для решения сложных многократных задач логического рассуждения в различных областях, включая числовое, табличное и знаниевое рассуждение. Он использует унифицированный подход с генератором действий, который предсказывает шаги и выбирает соответствующие инструменты, настроенные из сильных базовых моделей. Эксперименты показывают, что HUSKY проявляет стабильность в решении задач, благодаря тренировке как в определенных областях, так и в общей области знаний. Варианты с различными специализированными моделями для рассуждения на коде и математике подчеркивают влияние выбора модели на производительность. Гибкая и масштабируемая архитектура HUSKY готова решать все разнообразные задачи логического рассуждения, предоставляя план разработки продвинутых языковых агентов.
“`

























