«`html
Продвижение искусственного интеллекта в бизнесе
Языковые модели являются ключевыми в развитии искусственного интеллекта (ИИ), улучшая способность машин обрабатывать и генерировать текст, схожий с человеческим. Однако существует вызов в разработке моделей, способных управлять обширными данными без высоких вычислительных затрат.
Решения в области языковых моделей
Существующие исследования в области больших языковых моделей (LLM) включают в себя такие основополагающие фреймворки, как GPT-3 от OpenAI и BERT от Google. Модели, такие как LLaMA от Meta и T5 от Google, сосредоточены на повышении эффективности обучения и вывода. Инновации, такие как Sparse и Switch Transformers, исследуют более эффективные механизмы внимания, а также архитектуры Mixture-of-Experts (MoE), соответственно.
DeepSeek-V2: новаторская модель
DeepSeek-AI представили DeepSeek-V2, использующую инновационный архитектурный подход MoE и механизм Multi-head Latent Attention (MLA), что позволяет активировать лишь часть общего количества параметров на задачу, существенно снижая вычислительные затраты при высокой производительности.
Практические результаты
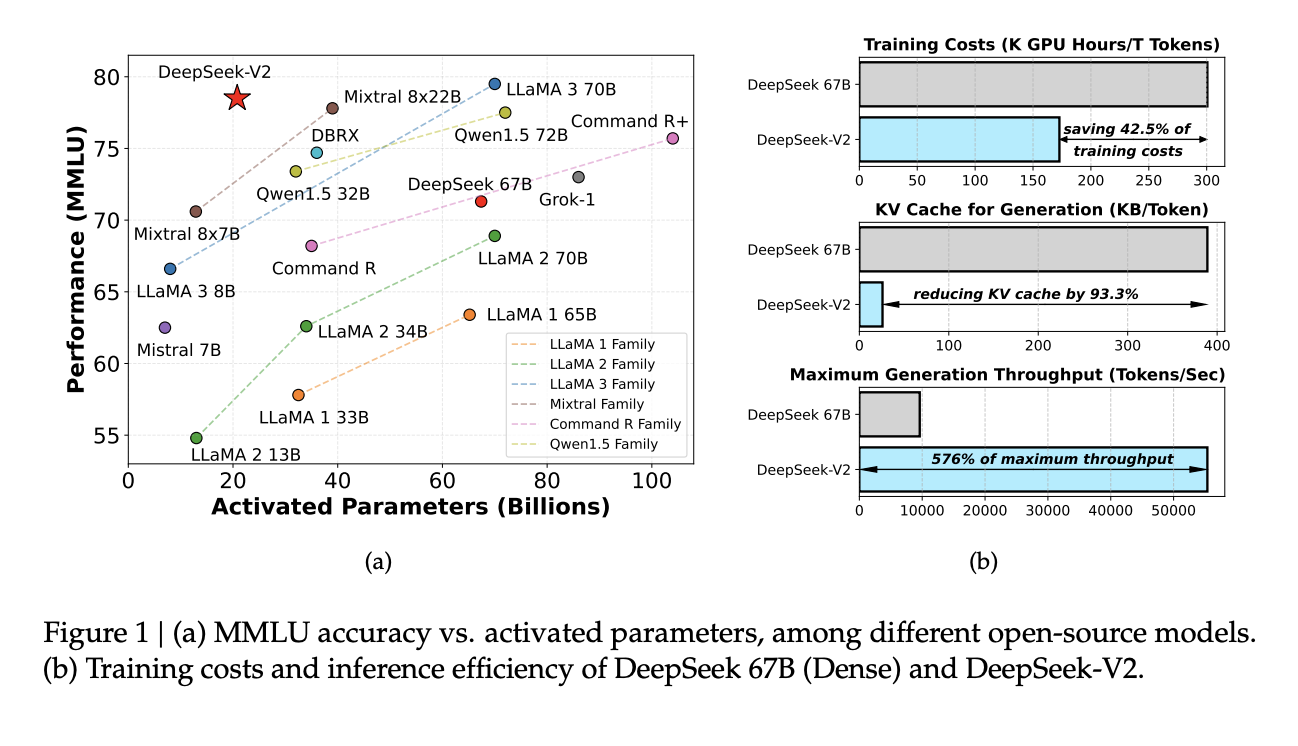
DeepSeek-V2 продемонстрировала значительное улучшение в эффективности и производительности. По сравнению с предшественником, DeepSeek 67 B, модель сократила затраты на обучение на 42,5% и размер кэша Key-Value на 93,3%. Более того, она увеличила максимальную производительность на 5,76 раза. В бенчмарк-тестах DeepSeek-V2 с 21 миллиардом активированных параметров последовательно превосходила другие модели с открытым исходным кодом, занимая высокие позиции по различным показателям производительности в различных языковых задачах.
Заключение
DeepSeek-V2 представляет значительные достижения в технологии языковых моделей благодаря своей архитектуре Mixture-of-Experts и механизму Multi-head Latent Attention. Модель успешно снижает вычислительные затраты, улучшая производительность, что подтверждается существенным сокращением затрат на обучение и улучшением скорости обработки. Показав себя эффективной на различных бенчмарках, DeepSeek-V2 устанавливает новые стандарты для эффективных масштабируемых моделей ИИ, что делает ее важным достижением для будущих приложений в обработке естественного языка и за его пределами.
«`

























