«`html
QoQ и QServe: новый этап в квантовании моделей, трансформирующий развертывание больших языковых моделей
Квантование, метод, неотъемлемый для вычислительной лингвистики, является ключевым для управления огромными вычислительными требованиями при развертывании больших языковых моделей (LLM). Он упрощает данные, облегчая более быстрые вычисления и более эффективную производительность модели. Однако развертывание LLM является сложным из-за их колоссального размера и вычислительной интенсивности. Эффективные стратегии развертывания должны сбалансировать производительность, точность и вычислительные накладные расходы.
Инновационное решение в квантовании
Исследователи из MIT, NVIDIA, UMass Amherst и MIT-IBM Watson AI Lab представили алгоритм Quattuor-Octo-Quattuor (QoQ), новый подход, улучшающий квантование. Этот инновационный метод использует постепенное групповое квантование, которое смягчает потери точности, обычно связанные со стандартными методами квантования. Путем квантования весов до промежуточной точности и их дальнейшего уточнения до целевой точности алгоритм QoQ обеспечивает адаптацию всех вычислений к возможностям GPU текущего поколения.
Практические решения и результаты
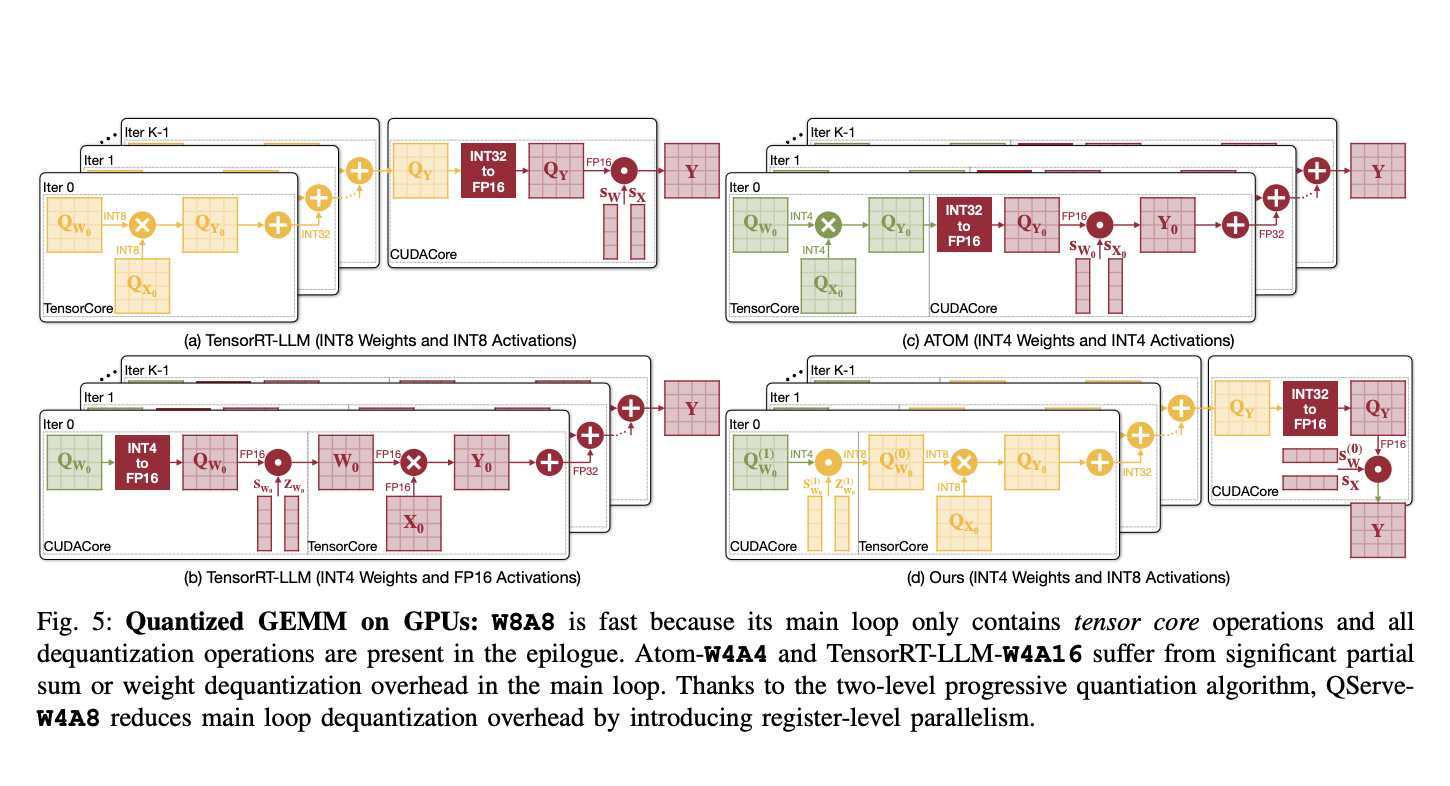
Алгоритм QoQ использует двухэтапный процесс квантования. Сначала веса квантуются до 8 бит с использованием масштабов FP16 для каждого канала; затем эти промежуточные данные квантуются до 4 бит. Этот подход позволяет выполнение операций General Matrix Multiplication (GEMM) на INT8 тензорных ядрах, увеличивая вычислительную пропускную способность и снижая задержку. Алгоритм также включает SmoothAttention, технику, которая корректирует квантование ключей активации для дальнейшей оптимизации производительности.
Для поддержки развертывания алгоритма QoQ была разработана система QServe. QServe обеспечивает настраиваемое рабочее окружение, максимизирующее эффективность LLM путем использования полного потенциала алгоритма. Она интегрируется без проблем с текущими архитектурами GPU, облегчая операции на низкопропускных ядрах CUDA и значительно увеличивая скорость обработки. Этот дизайн системы снижает накладные расходы на квантование путем акцентирования на вычислительно-ориентированной перестановке весов и объединенных механизмах внимания, важных для поддержания пропускной способности и минимизации задержки в реальном времени.
Оценки производительности алгоритма QoQ показывают существенные улучшения по сравнению с предыдущими методами. В тестировании QoQ увеличил максимальную достижимую пропускную способность моделей Llama-3-8B на GPU NVIDIA A100 до 1,2 раза и на GPU L40S до 1,4 раза. На платформе L40S система QServe достигла увеличения пропускной способности до 3,5 раза по сравнению с той же моделью на GPU A100, что значительно снизило стоимость обслуживания LLM.
В заключение, данное исследование представляет алгоритм QoQ и систему QServe как революционные решения для эффективного развертывания LLM. Путем решения значительных вычислительных накладных расходов и потерь точности, характерных для традиционных методов квантования, QoQ и QServe значительно улучшают пропускную способность обслуживания LLM. Результаты реализации показывают увеличение производительности на передовых GPU до 2,4 раза, что существенно снижает вычислительные требования и экономические затраты, связанные с развертыванием LLM. Этот прогресс устанавливает основу для более широкого применения и более эффективного использования больших языковых моделей в реальных приложениях.
«`

























