«`html
Исследование в области вычислительной лингвистики продолжает исследовать, как большие языковые модели (LLM) могут быть адаптированы для интеграции новых знаний без ущерба для целостности существующей информации.
Одним из ключевых вызовов является обеспечение точности этих моделей, фундаментальных для различных приложений обработки языка, даже при расширении их баз знаний.
Практические решения:
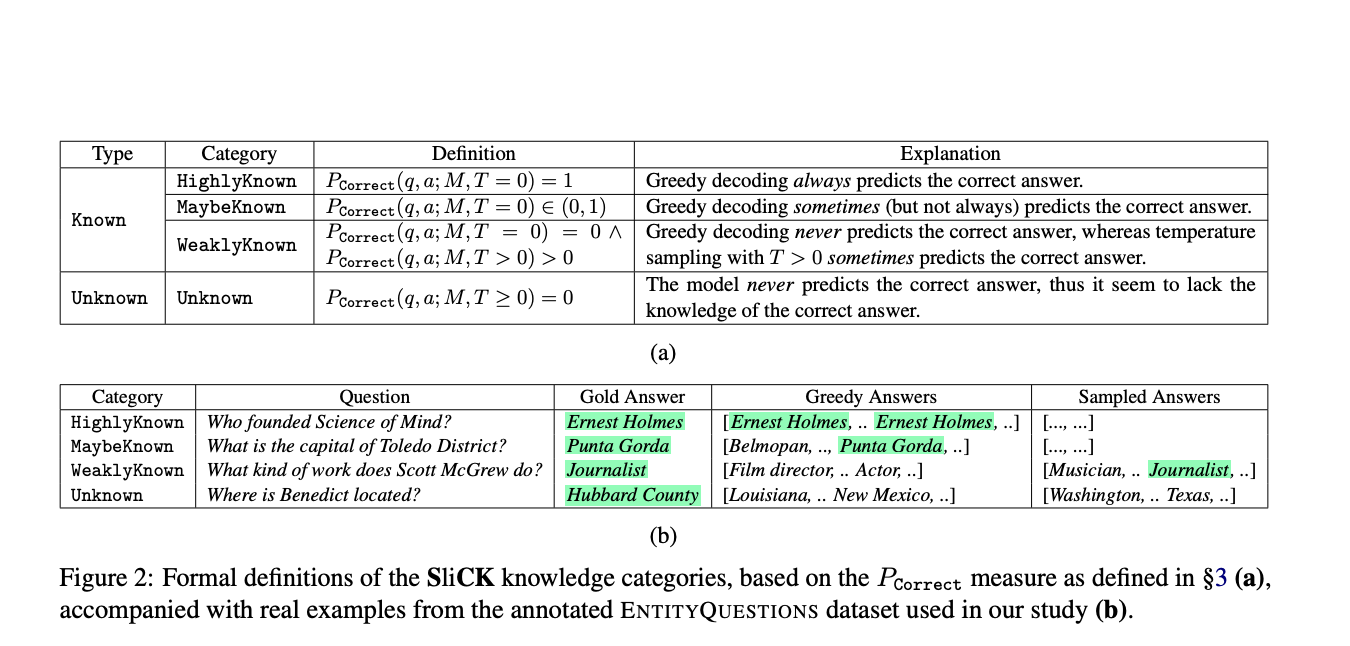
Применение структурированного подхода к обучению моделей, основанного на категоризации знаний и контролируемом соотношении известной и неизвестной информации, позволяет точно оценить способность модели ассимилировать новые факты, сохраняя точность существующей базы знаний.
Исследование демонстрирует, что модели, обученные с использованием структурированного подхода, показывают оптимизированный баланс, достигая более высокой точности в генерации правильных ответов по сравнению с моделями, обученными с преобладанием неизвестных данных.
Важность стратегической категоризации данных для улучшения надежности и производительности модели подчеркивает ценность данного исследования для будущих разработок в области методологий машинного обучения.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта.
«`

























