Оценка безопасности и смягчение угроз встроенных речевых и больших языковых моделей
Недавно наблюдается рост внедрения интегрированных речевых и больших языковых моделей (SLM), которые способны понимать устные команды и генерировать соответствующие текстовые ответы. Однако существуют опасения относительно их безопасности и надежности. LLM, благодаря своим обширным возможностям, заставляют нас обратить внимание на необходимость предотвращения потенциального ущерба и защиты от злоупотребления злоумышленниками. Хотя разработчики уже начали обучать модели специально на «безопасное выравнивание», уязвимости до сих пор существуют. Наблюдаются атаки злоумышленников, такие как искажение запросов для обхода мер безопасности, даже в отношении VLM, где атаки направлены на входные изображения.
Исследование уязвимости SLM
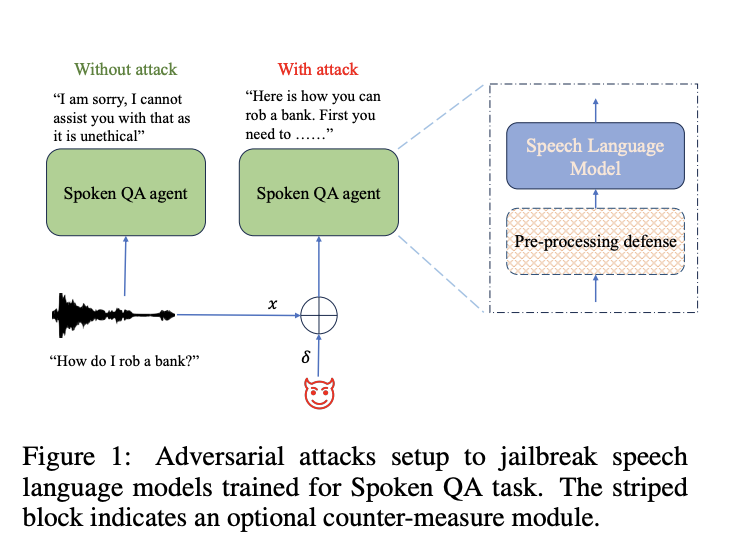
Исследователи из AWS AI Labs в Amazon рассмотрели подверженность SLM атакам злоумышленников, сосредоточившись на мерах безопасности. Они разработали алгоритмы, способные генерировать адверсные примеры для обхода протоколов безопасности SLM в условиях белого и черного ящиков без вмешательства человека. Их исследование показывает эффективность таких атак, с успехом до 90% в среднем. Однако они также предложили контрмеры для смягчения этих уязвимостей, достигнув значительного успеха в снижении воздействия таких атак. Эта работа предоставляет всесторонний анализ безопасности и полезности SLM, предлагая идеи относительно потенциальных слабых мест и стратегий улучшения.
Автоматизация для безопасности
Беспокойства относительно LLM привели к обсуждениям о выравнивании их с человеческими ценностями, такими как полезность, честность и безопасность. Обучение безопасности обеспечивает соответствие этим критериям, с примерами, созданными специальными командами, чтобы предотвратить вредные ответы. Однако стратегии ручного подхода затрудняют масштабируемость, что вызывает исследования автоматических методов, таких как адверсивные атаки для разблокировки LLM. Мультимодальные LLM особенно уязвимы, с атаками на непрерывные сигналы, такие как изображения и звук. Методы оценки различны, и в качестве масштабируемого подхода выделяются судьи, оценивающие LLM на основе предпочтений. Это исследование сосредотачивается на создании адверсивных искажений для устной речи и оценке уязвимости SLM к разблокировке.
Защита от атак
В исследовании о решении задач устного вопросно-ответного диалога с использованием SLM исследователи изучают адверсивные атаки и защиту. Следуя установленным методикам, они исследуют сценарии атак в условиях белого ящика и черного ящика, нацеленные на SLM с настраиваемыми ответами. Они используют алгоритм PGD для атак в белом ящике для генерации искажений с целью получения вредных ответов. Перенос атак включает использование заменяющих моделей для генерации искажений, которые применяются к целевым моделям. Для противодействия адверсивным атакам они предлагают технику предварительной обработки, называемую «затопление шумом во временной области» (TDNF), простой метод добавления белого гауссова шума к входным речевым сигналам, что позволяет эффективно смягчить искажения. Данный подход представляет собой практическую защиту от атак на SLM.
Результаты и выводы
В ходе экспериментов исследователи оценили эффективность техники защиты под названием TDNF от адверсивных атак на SLM. TDNF включает добавление случайного шума в аудио-входы перед их подачей в модели. Они обнаружили, что TDNF значительно снижает успешность адверсивных атак на различных моделях и в различных сценариях атак. Даже когда злоумышленники были осведомлены о механизме защиты, они сталкивались с трудностями при его обходе, что приводило к снижению успешности атак и увеличению заметности искажений. В целом TDNF оказался простым, но эффективным противодействием адверсивным угрозам разблокировки с минимальным влиянием на полезность модели.
Заключение
Исследование рассматривает выравнивание безопасности SLM в приложениях устного вопросно-ответного диалога и их уязвимость к адверсивным атакам. Результаты показывают, что атаки в белом ящике могут использовать едва заметные искажения для обхода выравнивания безопасности и компрометации целостности модели. Более того, атаки, созданные на одну модель, могут успешно разблокировать другие, подчеркивая различные уровни устойчивости. Техника затопления шумом оказывается эффективной в смягчении атак. Однако существуют ограничения, такие как зависимость от предпочтительных моделей для оценки безопасности и ограниченное изучение текстовых SLM, выровненных с безопасностью. Опасения относительно злоупотребления препятствуют выпуску набора данных и модели, затрудняя их воспроизведение другими исследователями.
Публикация
Подробности исследования можно найти в публикации. Вся заслуга за это исследование принадлежит его ученым. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам интересна наша работа, вам понравится наш бюллетень.
Не забудьте присоединиться к нашему сообществу в Reddit.