TRANSMI: Решение для улучшения кросс-языкового обучения
Растущая доступность цифрового текста на различных языках и алфавитах представляет значительную сложность для обработки естественного языка (NLP). Мультиязычные предварительно обученные языковые модели (mPLM) часто испытывают трудности в обработке транслитерированных данных, что приводит к снижению производительности. Решение этой проблемы критично для улучшения кросс-языкового обучения и обеспечения точных приложений обработки естественного языка на различных языках и алфавитах, что является важным для глобальной коммуникации и обработки информации.
Практические решения и ценность
Текущие методы, включая модели XLM-R и Glot500, хорошо справляются с текстом на исходных алфавитах, но испытывают затруднения с транслитерированным текстом из-за неоднозначностей и проблем токенизации. Эти ограничения снижают их производительность в кросс-языковых задачах, делая их менее эффективными при обработке текста, преобразованного в общий алфавит, такой как латиница. Неспособность этих моделей точно интерпретировать транслитерации создает значительное препятствие для их использования в мультиязычных средах.
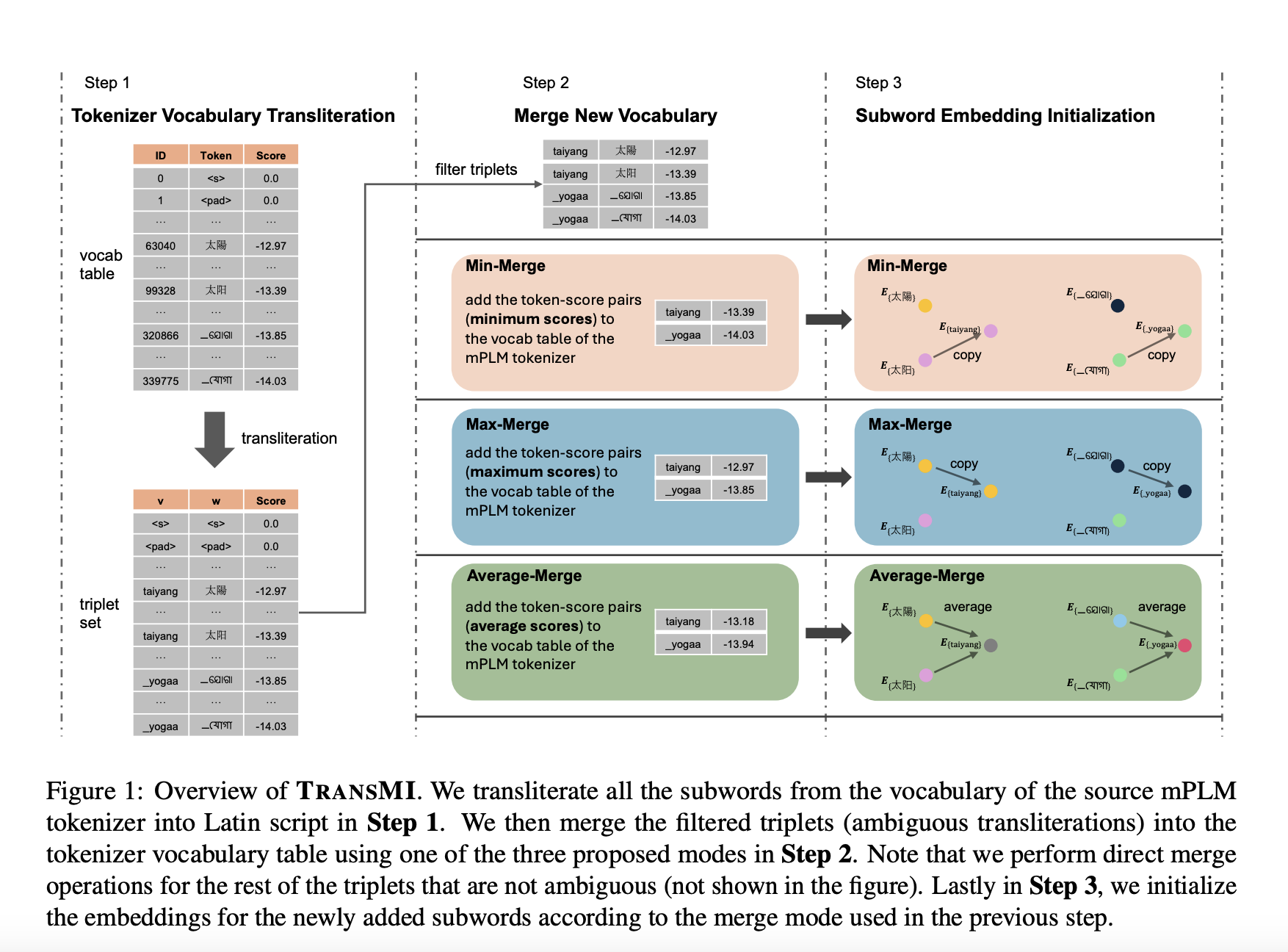
Исследователи из Центра информационной обработки и языков ЛМУ в Мюнхене и Мюнхенского центра машинного обучения (MCML) представили TRANSMI, фреймворк, разработанный для улучшения мультиязычных предварительно обученных языковых моделей для транслитерированных данных без дополнительного обучения. TRANSMI модифицирует существующие mPLM, используя три режима объединения — Min-Merge, Average-Merge и Max-Merge — для включения транслитерированных подслов в их словари, тем самым решая проблемы транслитерации и улучшая производительность кросс-языковых задач.
TRANSMI интегрирует новые подслова, адаптированные для транслитерированных данных, в словари mPLM, преуспевая особенно в режиме Max-Merge для языков с высокими ресурсами. Фреймворк тестировался на наборах данных, включающих транслитерированные версии текстов на алфавитах, таких как кириллица, арабский и деванагари, показывая, что модифицированные с помощью TRANSMI модели превосходят свои оригинальные версии в задачах, таких как извлечение предложений, классификация текста и маркировка последовательностей.
Эти улучшения подчеркивают потенциал TRANSMI как эффективного инструмента для улучшения мультиязычных NLP-моделей, обеспечивая лучшую обработку транслитерированных данных и повышая точность кросс-языковой обработки.
Заключение
TRANSMI решает критическую проблему улучшения производительности mPLM на транслитерированных данных путем модификации существующих моделей без дополнительного обучения. Этот фреймворк улучшает способность mPLM обрабатывать транслитерации, что приводит к значительным улучшениям в кросс-языковых задачах. TRANSMI предлагает практичное и инновационное решение для сложной проблемы, создавая прочную основу для дальнейших достижений в мультиязычной обработке естественного языка и улучшении глобальной коммуникации и обработки информации.

























