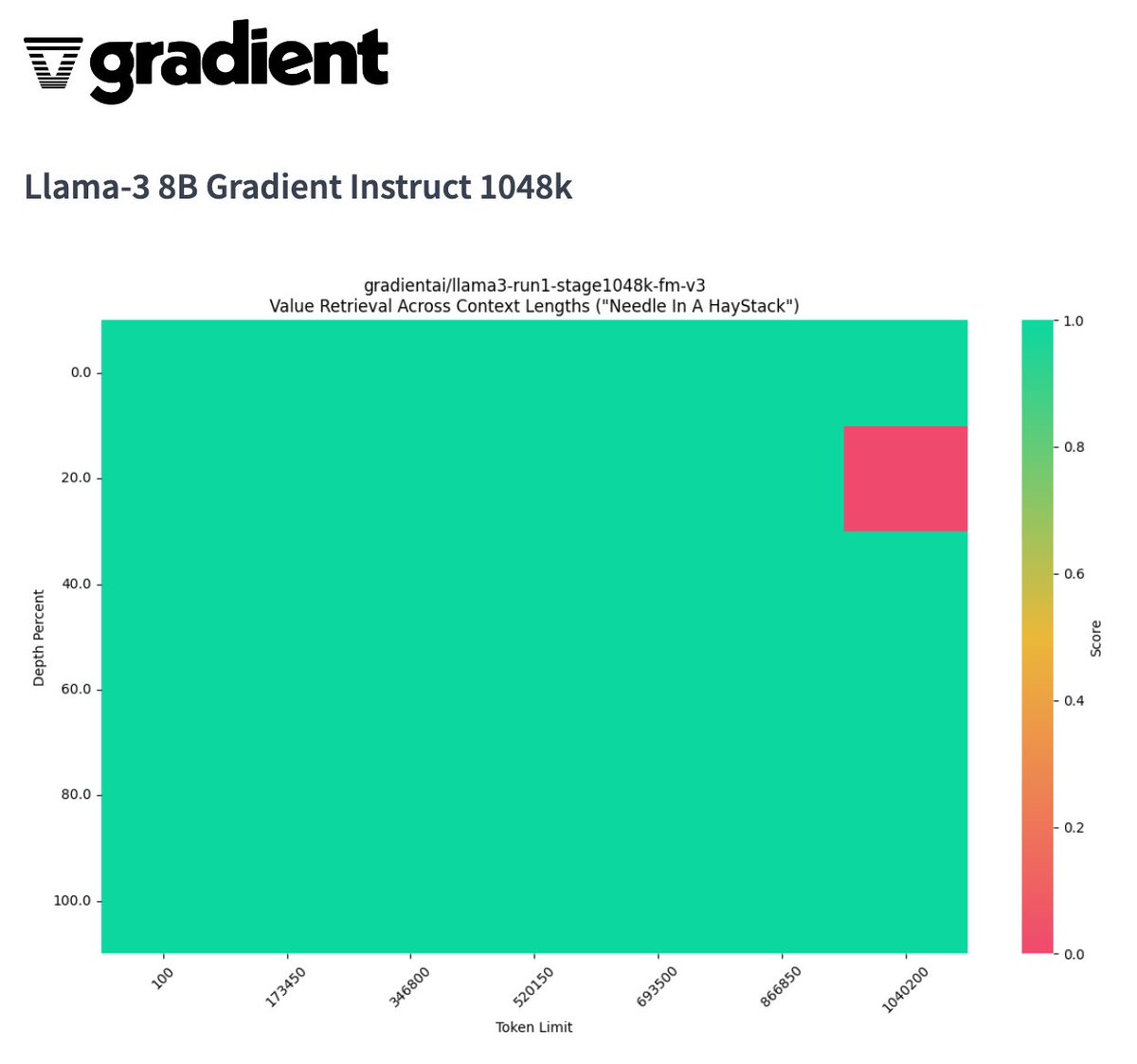
Новый стандарт в области долгоконтекстных ИИ-моделей: Llama-3 8B Gradient Instruct 1048k
Языковые модели разработаны для понимания и генерации человеческого языка. Они играют важную роль в создании чат-ботов, автоматизированного создания контента и анализа данных. Однако их способность понимать и генерировать текст зависит от длины контекста, что делает развитие моделей с долгим контекстом особенно значимым для улучшения возможностей ИИ.
Преодоление ограничений
Одной из основных проблем в области языковых моделей ИИ является эффективная обработка и понимание длинных текстовых последовательностей. Традиционные модели часто испытывают трудности при обработке контекстов длиной более нескольких тысяч токенов, что затрудняет поддержание связности и актуальности в длинных взаимодействиях. Это ограничение мешает применению ИИ в областях, требующих обширного контекста, таких как анализ юридических документов, длительные разговоры и техническое письмо.
Новое решение
Благодаря поддержке Crusoe Energy, исследователи из Gradient представили модель Llama-3 8B Gradient Instruct 1048k, которая расширяет длину контекста с 8 000 до более 1 048 000 токенов. Это значительное улучшение позволяет модели обрабатывать обширные данные без типичного снижения производительности, связанного с длинными контекстами.
Практические применения
Модель Llama-3 8B Gradient Instruct 1048k демонстрирует высокую производительность в таких областях, как генерация кода, анализ инвестиций, обработка данных и юридический анализ. Это подчеркивает способность модели эффективно обрабатывать детальные и контекстно-насыщенные задачи.
Заключение
Внедрение модели Llama-3 8B Gradient Instruct 1048k открывает новые возможности для применения ИИ в различных областях. Это улучшает связность и актуальность контента, создаваемого ИИ, и повышает общую полезность языковых моделей в реальных сценариях.

























