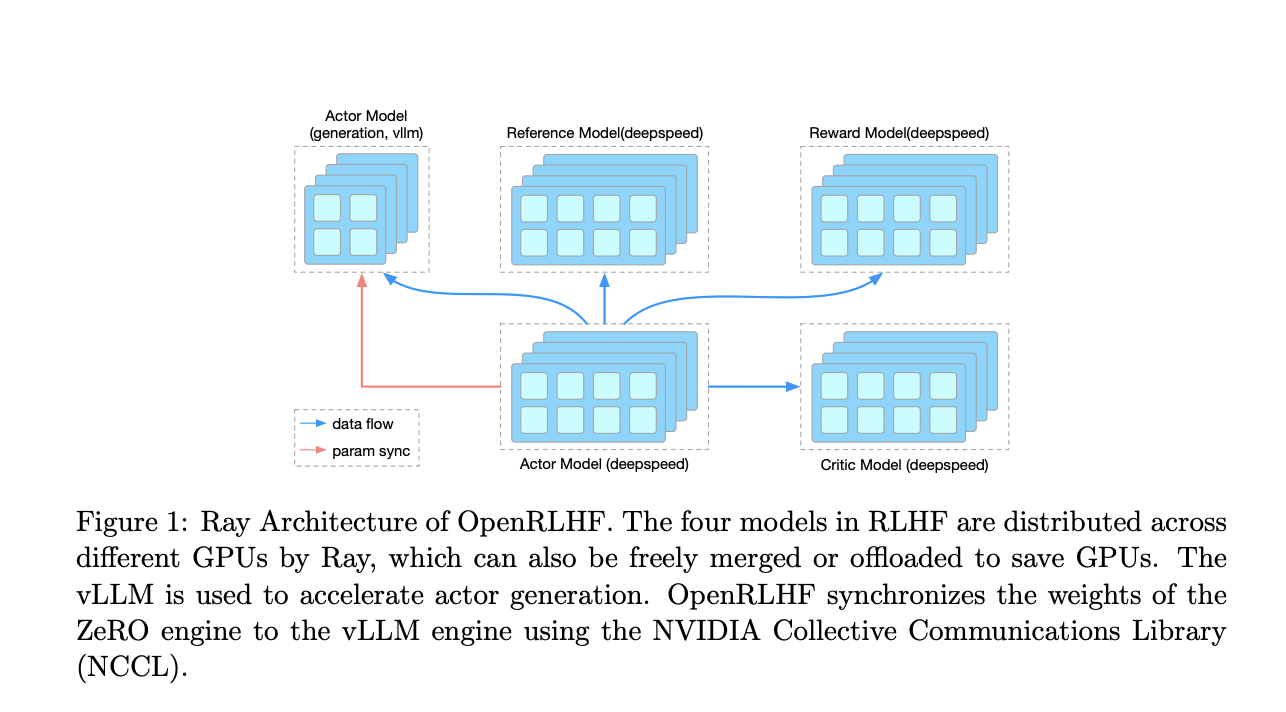
«`html
Искусственный интеллект: новые возможности и практические решения
Искусственный интеллект стремительно развивается, особенно в области обучения масштабных языковых моделей (LLM) с параметрами более 70 миллиардов. Эти модели стали неотъемлемыми для различных задач, включая генерацию творческого текста, перевод и создание контента. Однако эффективное использование мощи таких продвинутых LLM требует вмешательства человека через технику, известную как обучение с подкреплением от обратной связи человека (RLHF). Основная проблема возникает из-за того, что существующие структуры RLHF борются с огромными требованиями к памяти для работы с этими колоссальными моделями, что ограничивает их полный потенциал.
Проблемы и практические решения
Текущие подходы RLHF часто включают разделение LLM на несколько GPU для обучения, но эта стратегия не без недостатков. Во-первых, избыточное разделение может привести к фрагментации памяти на отдельных GPU, что приведет к уменьшению эффективного размера пакета для обучения и замедлит весь процесс. Во-вторых, коммуникационные накладные расходы между фрагментированными частями создают узкие места, аналогичные команде, постоянно обменивающейся сообщениями, что в конечном итоге затрудняет эффективность.
OpenRLHF: новаторский фреймворк
В ответ на эти проблемы исследователи предлагают новаторский фреймворк RLHF под названием OpenRLHF. OpenRLHF использует две ключевые технологии: Ray, распределенный планировщик задач, и vLLM, распределенный движок вывода. Ray функционирует как сложный менеджер проекта, интеллектуально распределяя LLM по GPU без избыточного разделения, тем самым оптимизируя использование памяти и ускоряя обучение путем возможности использования больших размеров пакетов на GPU. В свою очередь, vLLM улучшает скорость вычислений, используя параллельные возможности обработки нескольких GPU, подобно сети высокопроизводительных компьютеров, сотрудничающих над сложной задачей.
Практические результаты и ценность
Подробный сравнительный анализ с установленным фреймворком, таким как DSChat, проведенный во время обучения масштабной модели LLaMA2 с 7 миллиардами параметров, продемонстрировал значительные улучшения с помощью OpenRLHF. Он достиг более быстрой сходимости обучения, подобной тому, как студент быстро усваивает концепцию благодаря более эффективному подходу к обучению. Более того, быстрые возможности генерации vLLM привели к существенному сокращению общего времени обучения, подобно тому, как производственный завод увеличивает скорость производства с помощью оптимизированной линии сборки. Кроме того, интеллектуальное планирование Ray минимизировало фрагментацию памяти, позволяя использовать большие размеры пакетов и ускоряя обучение.
Заключение
Прорыв OpenRLHF не только решает, но и устраняет основные препятствия при обучении колоссальных LLM с использованием RLHF. За счет использования мощности эффективного планирования и ускоренных вычислений он преодолевает ограничения памяти и достигает более быстрой сходимости обучения. Это открывает пути для тонкой настройки еще более крупных LLM с обратной связью от человека, заложив основу для новой эры приложений в обработке языка и взаимодействии с информацией, которая потенциально может революционизировать различные области.
Подробнее ознакомьтесь с документацией и GitHub.
Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram каналу, Discord каналу и LinkedIn группе.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit с более чем 42 тысячами участников.