«`html
Эффективное снижение потребления памяти и увеличение пропускной способности в LLMs
Эффективное развертывание больших языковых моделей (LLMs) требует высокой производительности и низкой задержки. Однако значительное потребление памяти LLM, особенно кэшем ключ-значение (KV), мешает достижению больших размеров пакетов и высокой производительности. Кэш KV, хранящий ключи и значения во время генерации, потребляет более 30% памяти GPU. Различные подходы, такие как сжатие последовательностей KV и динамические политики вытеснения кэша, направлены на смягчение этой памяти в LLMs.
Практические решения:
- Внедрение пaged attention для снижения фрагментации памяти.
- Сжатие запросов, удаление избыточности входного контекста и постепенное сжатие токенов.
- Обрезка неважных токенов, применение различных стратегий обрезки к attention heads и хранение только важных токенов.
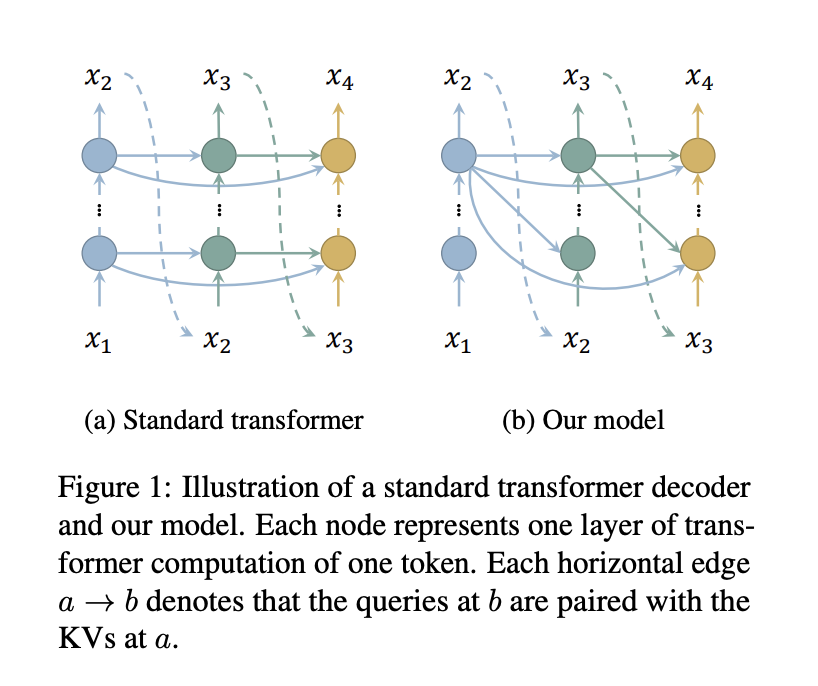
Исследователи из Школы информационных наук и технологий Университета ШанхайТек и Шанхайского инженерного центра интеллектуального зрения и изображений представляют эффективный подход к снижению потребления памяти в кэше KV декодеров трансформаторов путем уменьшения числа кэшируемых слоев. Парное соединение запросов всех слоев с ключами и значениями только верхнего слоя позволяет кэшировать только ключи и значения одного слоя, что значительно экономит память без дополнительной вычислительной нагрузки.
Практические решения:
- Маскирование диагонали матрицы внимания для решения проблемы циклической зависимости.
- Сохранение стандартного внимания для нескольких слоев для поддержания синтаксическо-семантического шаблона, обеспечивая конкурентоспособную производительность с стандартными моделями.
Исследователи оценили свой метод, используя модели с 1,1 млрд, 7 млрд и 30 млрд параметров на различных GPU, включая NVIDIA GeForce RTX 3090 и A100. Оценка включает задержку и пропускную способность, результаты показывают значительно большие размеры пакетов и более высокую пропускную способность по сравнению со стандартными моделями Llama в различных настройках. Интеграция с StreamingLLM демонстрирует более низкую задержку и потребление памяти, с возможностью эффективной обработки токенов бесконечной длины.
Практические решения:
- Снижение потребления памяти и увеличение пропускной способности в LLMs.
- Интеграция с другими методами экономии памяти, такими как StreamingLLM.
Это исследование представляет надежный метод снижения потребления памяти и увеличения пропускной способности в LLMs путем минимизации числа слоев, требующих вычисления ключей и значений. Эмпирические результаты демонстрируют существенное снижение потребления памяти и улучшение пропускной способности с минимальной потерей производительности.
«`

























