LANISTR: Решение для эффективной работы с мультимодальными данными
Google Cloud AI Researchers представили LANISTR для решения проблем эффективной обработки неструктурированных и структурированных данных в рамках единой системы. В машинном обучении обработка мультимодальных данных, включающих язык, изображения и структурированные данные, становится все более важной. Одной из ключевых проблем является отсутствие модальностей в масштабных неразмеченных и структурированных данных, таких как таблицы и временные ряды. Традиционные методы часто не справляются, если один или несколько типов данных отсутствуют, что приводит к неоптимальной производительности модели.
Практические решения и ценность
Методы предварительного обучения мультимодальных данных обычно зависят от наличия всех модальностей во время обучения и вывода, что часто невозможно в реальных сценариях. Методы включают различные формы техник раннего и позднего объединения, где данные из разных модальностей объединяются либо на уровне признаков, либо на уровне принятия решений. Однако эти подходы не подходят для ситуаций, когда одна или несколько модальностей могут быть полностью отсутствующими или неполными.
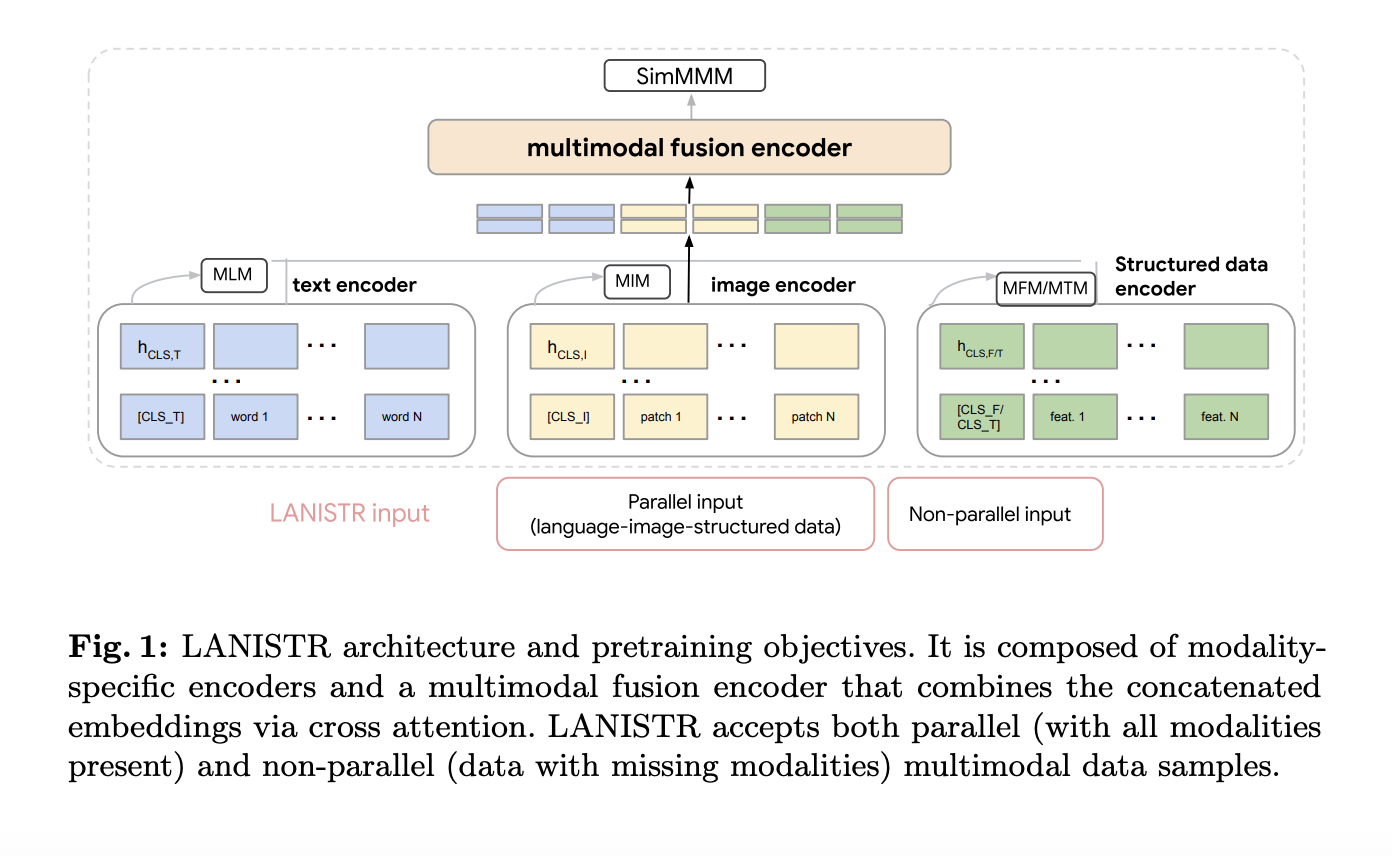
LANISTR (Language, Image, and Structured Data Transformer) от Google представляет собой новую предварительную систему обучения, использующую стратегии унимодальной и мультимодальной маскировки для создания надежной цели предварительного обучения, способной эффективно обрабатывать отсутствующие модальности. Фреймворк основан на инновационной цели маскировки мультимодальных данных на основе сходства, что позволяет ему учиться на доступных данных, делая обоснованные предположения о отсутствующих модальностях.
LANISTR показал эффективность в сценариях вне распределения, где модель сталкивалась с данными, не встречавшимися во время обучения. Эта устойчивость к разнообразию данных является ключевой в реальных приложениях, где изменчивость данных является общей проблемой. LANISTR достиг значительного увеличения точности и обобщения даже при наличии размеченных данных.
В заключение, LANISTR решает критическую проблему в области мультимодального машинного обучения: проблему отсутствия модальностей в масштабных неразмеченных наборах данных. Путем использования нового сочетания стратегий унимодальной и мультимодальной маскировки, а также цели маскировки мультимодальных данных на основе сходства, LANISTR обеспечивает надежное и эффективное предварительное обучение.

























