Эффективные стратегии генерации текста с заданным уровнем владения языком
Контроль уровней владения языком в текстах, создаваемых большими языковыми моделями (LLM), представляет существенную проблему в исследованиях в области искусственного интеллекта. Уверенность в том, что создаваемый контент соответствует различным уровням владения языком, критически важна для приложений в обучении языку, образовании и других областях, где пользователи могут быть не полностью владеющими целевым языком. Без эффективного контроля уровня владения качество и эффективность создаваемого LLM-контента существенно страдают, особенно для неносителей языка, детей и изучающих язык.
Практические решения и ценность
В настоящее время существуют методы решения этой проблемы, такие как few-shot prompting, supervised finetuning и reinforcement learning (RL). Модель CALM (CEFR-Aligned Language Model) разработана с целью сочетания этих методов для обеспечения высококачественного контента, соответствующего уровням владения в CEFR. Такой подход дополняет существующие методы и снижает затраты по сравнению с использованием проприетарных моделей, представляя значительный вклад в область.
Ключевые решения метода CALM включают в себя использование открытых моделей, таких как LLama-2-7B и Mistral-7B, с последующим обучением с использованием PPO для выравнивания результатов модели с желаемыми уровнями владения языком. Введена также стратегия выборки, которая повышает производительность модели путем выбора лучшего результата из нескольких поколений. Технические аспекты включают использование лингвистических характеристик для автоматизированной оценки CEFR и применение RL-техник для минимизации ControlError, который измеряет отклонение созданного текста от целевого уровня владения.
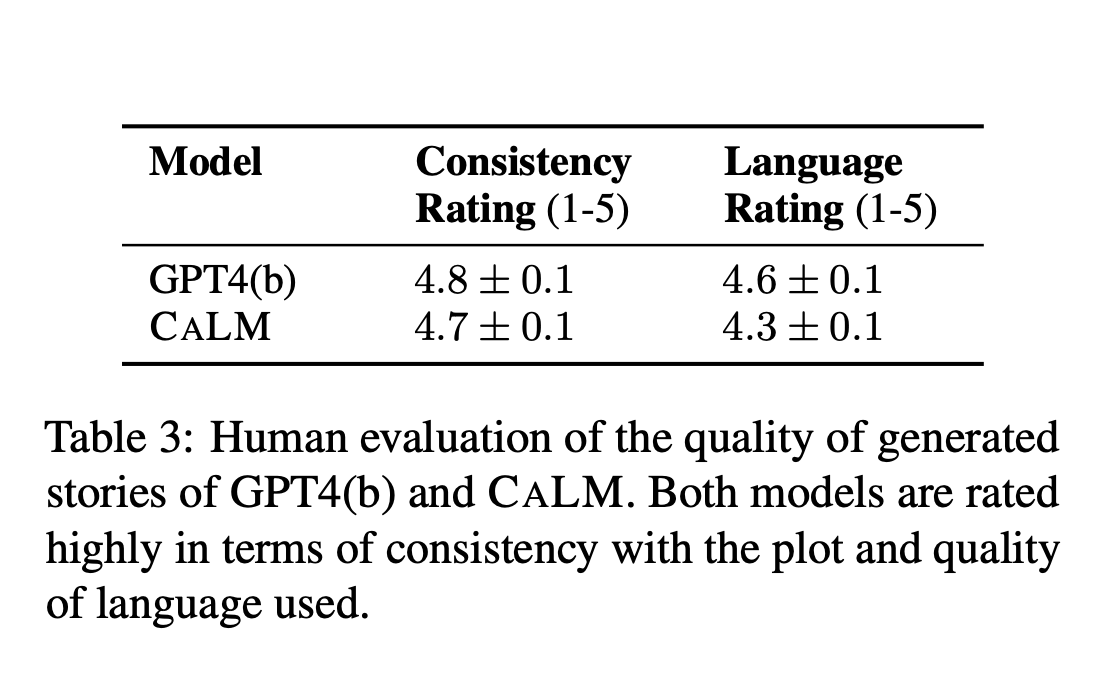
Результаты демонстрируют, что модель CALM достигает сопоставимого с GPT-4 уровня ControlError при существенном снижении затрат. Оценочные метрики включают ControlError, QualityScore и вычислительные затраты. Исследование подтверждено как автоматической оценкой, так и масштабным ее изучением. Ключевая таблица сравнивает различные стратегии и модели, выделяя превосходство CALM как в ControlError, так и качественных метриках.
Данная работа имеет потенциал улучшить применение в образовании и обучении языкам, делая передовые инструменты ИИ более доступными для широкой аудитории.
**Прочитать статью можно по ссылке [здесь](https://flycode.ru/).
**Подпишитесь на наш [Twitter](https://flycode.ru/).
**Присоединяйтесь к нашему каналу в [Telegram](https://t.me/flycodetelegram) и группе в [LinkedIn](https://flycode.ru/).
**Если вам нравится наша работа, вам понравится и наша [рассылка](https://flycode.ru/).
**Не забудьте присоединиться к нашему SubReddit по ML (более 44k участников) [здесь](https://flycode.ru/).

























