«`html
BigCode выпустил BigCodeBench: новый стандарт для оценки больших языковых моделей на реальных задачах программирования
BigCode, ведущий разработчик больших языковых моделей (LLM), объявил о выпуске BigCodeBench, нового бенчмарка, разработанного для тщательной оценки программных возможностей LLM на практических и сложных задачах.
Преодоление ограничений существующих бенчмарков
Существующие бенчмарки, такие как HumanEval, были ключевыми в оценке LLM по задачам генерации кода, но они сталкиваются с критикой из-за своей простоты и недостатка применимости в реальном мире. BigCodeBench был разработан для заполнения этой пробела. Он содержит 1,140 задач на уровне функций, которые вызывают LLM к выполнению инструкций, требующих сложного мышления и навыков решения проблем. Каждая задача тщательно разработана для имитации реальных сценариев, требующих сложного рассуждения и навыков решения проблем. Задачи дополнительно проверяются с помощью в среднем 5,6 тестовых случаев на задачу, достигая покрытия ветвей 99% для тщательной оценки.
Компоненты и возможности
BigCodeBench разделен на два основных компонента: BigCodeBench-Complete и BigCodeBench-Instruct. BigCodeBench-Complete фокусируется на завершении кода, где LLM должны завершить реализацию функции на основе подробных инструкций docstring. BigCodeBench-Instruct, с другой стороны, разработан для оценки LLM, настроенных на инструкции, которые следуют естественно-языковым инструкциям.
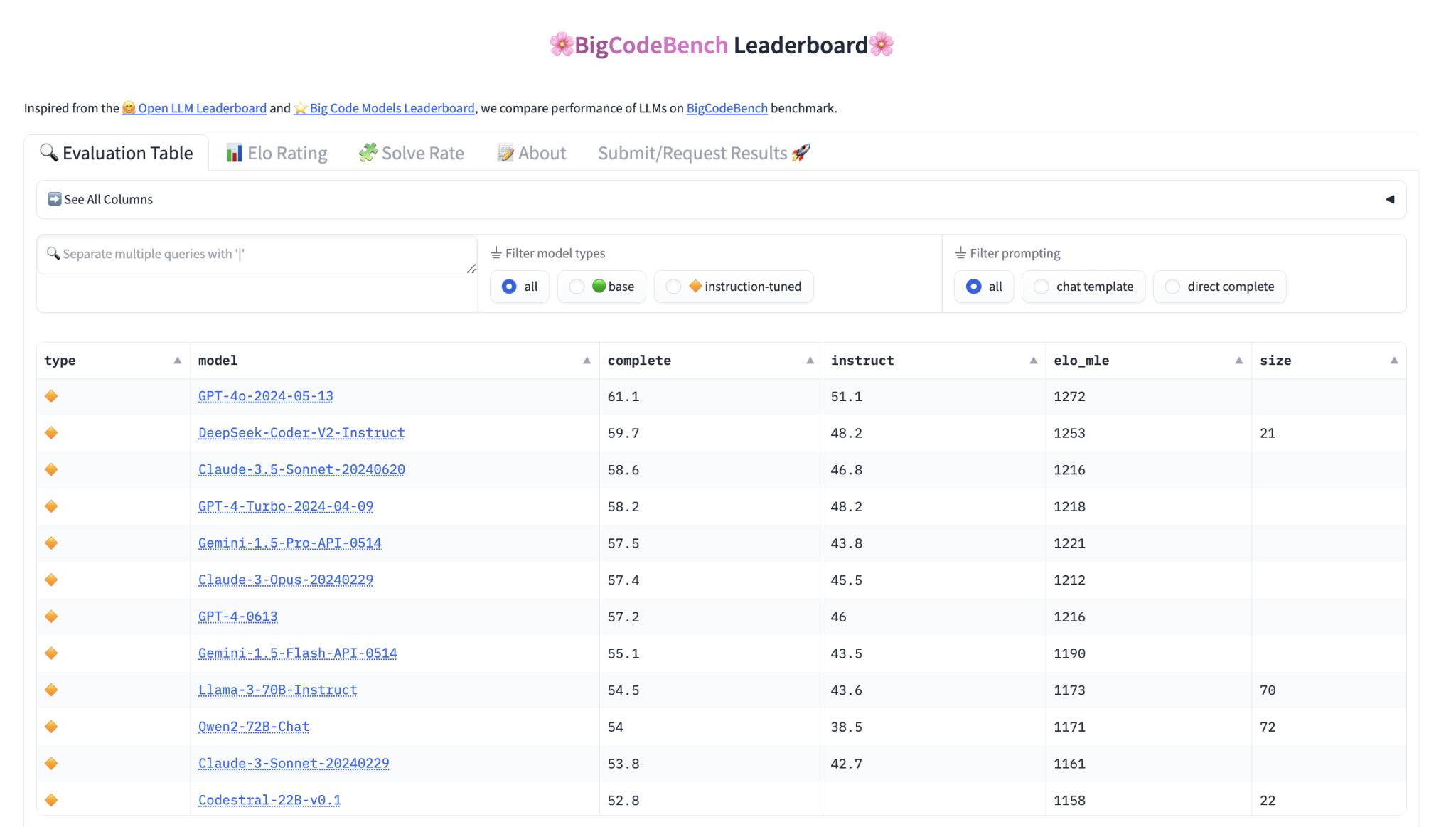
Фреймворк оценки и рейтинг
Для облегчения процесса оценки BigCode предоставил удобный фреймворк, доступный через PyPI, с подробными инструкциями установки и предварительно скомпилированными образами Docker для генерации и выполнения кода. Производительность моделей на BigCodeBench измеряется с помощью калиброванного Pass@1, метрики, оценивающей процент задач, правильно решенных с первой попытки. Эта метрика уточняется с использованием системы рейтинга Эло, аналогичной используемой в шахматах, для ранжирования моделей на основе их производительности по различным задачам.
Вовлечение сообщества и будущие разработки
BigCode призывает сообщество искусственного интеллекта взаимодействовать с BigCodeBench, предоставляя обратную связь и внося свой вклад в его развитие. Все артефакты, связанные с BigCodeBench, включая задачи, тестовые случаи и фреймворк оценки, являются открытыми и доступными на платформах, таких как GitHub и Hugging Face. Команда BigCode планирует постоянно улучшать BigCodeBench, обеспечивая многоязычную поддержку, увеличивая строгость тестовых случаев и гарантируя, что бенчмарк развивается вместе с продвижениями в программных библиотеках и инструментах.
Релиз BigCodeBench является значительным событием в оценке LLM для программных задач. BigCode стремится расширить границы того, что могут достичь эти модели, в конечном итоге стимулируя область искусственного интеллекта в разработке программного обеспечения.
Проверьте блог HF, рейтинг и код. Вся заслуга за этот проект принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу Telegram и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit ML с более чем 45 тыс. подписчиков.
Оригинал статьи: MarkTechPost