Продвинутые решения в области генеративных моделей
Машинное обучение сделало значительные успехи, особенно в области генеративных моделей, таких как диффузионные модели. Эти модели способны обрабатывать высокоразмерные данные, включая изображения и звук. Они находят применение в различных областях, таких как создание искусства и медицинское изображение, демонстрируя свою универсальность. Главное внимание уделяется улучшению этих моделей с учетом человеческих предпочтений, обеспечивая, что их результаты будут полезны и безопасны для широкого спектра применений.
Актуальные исследования и практические решения
Несмотря на значительные достижения, существующие генеративные модели часто нуждаются в помощи, чтобы наилучшим образом соответствовать человеческим предпочтениям. Это неправильное соответствие может привести к бесполезным или потенциально вредным результатам. Основная проблема заключается в том, чтобы настроить эти модели таким образом, чтобы они постоянно производили желательные и безопасные результаты, не ущемляя при этом свои генеративные возможности.
Существующие исследования включают техники обучения с подкреплением и стратегии оптимизации предпочтений, такие как Diffusion-DPO и SFT. Были применены методы, такие как Proximal Policy Optimization (PPO) и модели, такие как Stable Diffusion XL (SDXL). Кроме того, были адаптированы такие фреймворки, как оптимизация Канемана-Тверского (KTO) для текстово-графических диффузионных моделей. Хотя эти подходы улучшают соответствие человеческим предпочтениям, они зачастую не справляются с разнообразными стилистическими расхождениями и эффективным управлением памятью и вычислительными ресурсами.
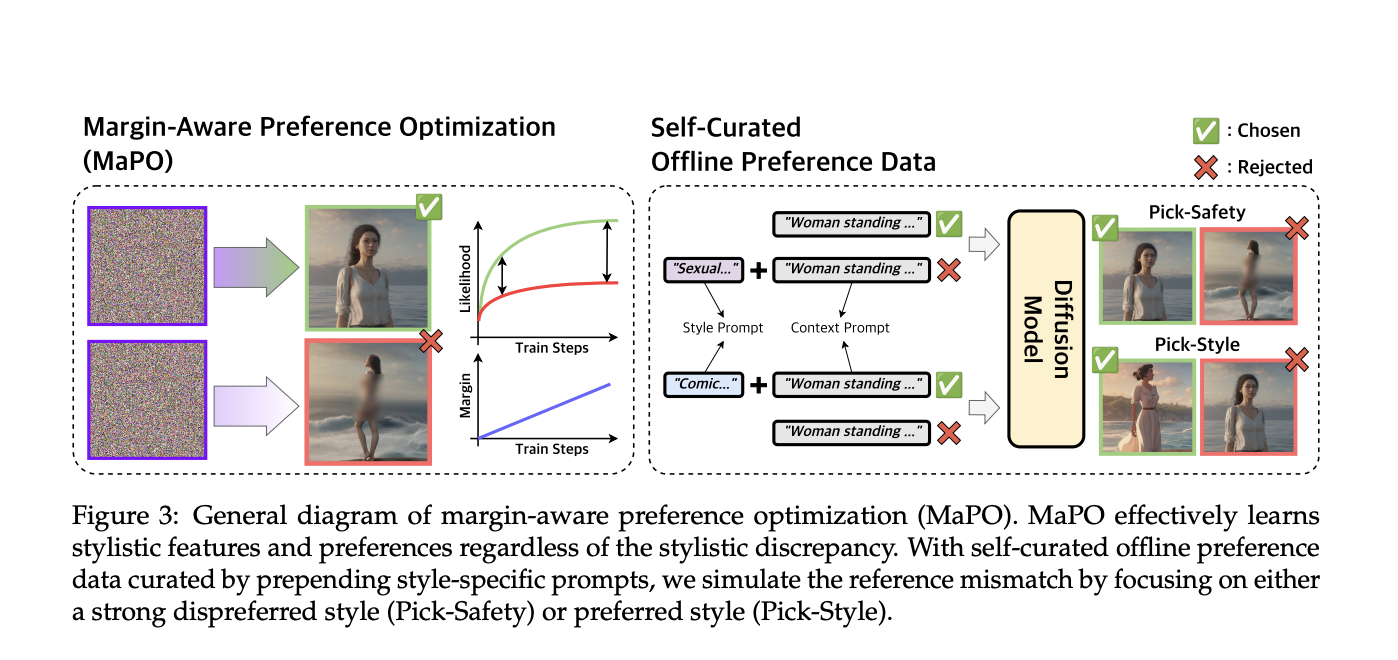
Исследователи из Корейского института науки и технологий (KAIST), Корейского университета и Hugging Face представили новый метод под названием Maximizing Alignment Preference Optimization (MaPO). Этот метод направлен на более эффективное настройку диффузионных моделей путем прямого включения данных о предпочтениях в процесс обучения. Научная команда провела обширные эксперименты для проверки своего подхода, обеспечивая, что он превзойдет существующие методы по показателям соответствия и эффективности.
Преимущества метода MaPO и его эффективность
MaPO улучшает диффузионные модели путем включения набора данных о предпочтениях в процесс обучения. Этот набор данных включает различные человеческие предпочтения, с которыми модель должна соответствовать, такие как безопасность и стилистические выборы. Метод включает уникальную функцию потерь, которая приоритезирует предпочтительные результаты, одновременно штрафуя менее желательные. Этот процесс настройки гарантирует, что модель генерирует результаты, близкие к ожиданиям человека, делая ее универсальным инструментом в различных областях. Методика, используемая MaPO, не зависит от какой-либо опорной модели, что отличает ее от традиционных методов. Максимизируя вероятность отличий между предпочтительными и непредпочтительными наборами изображений, MaPO изучает общие стилистические особенности и предпочтения, не переобучаясь на обучающих данных. Это делает метод дружелюбным к памяти и эффективным, подходящим для различных применений.
Производительность MaPO была оценена на нескольких тестах. Он продемонстрировал превосходное соответствие человеческим предпочтениям, достигнув более высоких оценок безопасности и стилистического соответствия. MaPO набрал 6,17 баллов в оценке эстетики и сократил время обучения на 14,5%, подчеркивая его эффективность. Более того, метод превзошел базовую модель Stable Diffusion XL (SDXL) и другие существующие методы, доказав свою эффективность в постоянном генерировании предпочтительных результатов.
Заключение: перспективы применения и преимущества
Метод MaPO представляет собой значительное достижение в соответствии генеративных моделей человеческим предпочтениям. Исследователи разработали более эффективное и эффективное решение путем прямого включения данных о предпочтениях в процесс обучения. Этот метод улучшает безопасность и полезность результатов модели и ставит новый стандарт для будущих разработок в этой области.
В общем, исследование подчеркивает важность прямой оптимизации предпочтений в генеративных моделях. Способность MaPO обрабатывать несоответствия опорных моделей и адаптироваться к различным стилистическим предпочтениям делает его ценным инструментом для различных применений. Данное исследование открывает новые перспективы для дальнейшего изучения оптимизации предпочтений, прокладывая путь для более персонализированных и безопасных генеративных моделей в будущем.

























