«`html
Google DeepMind представляет WARP: новый метод RLHF для оптимизации KL-наградного фронта решений и выравнивания LLMs
Метод обучения с подкреплением от обратной связи человека (RLHF) способствует генерации моделей с высокими наградами, используя модель вознаграждения, обученную на человеческих предпочтениях, для выравнивания больших языковых моделей (LLM). Однако RLHF имеет несколько нерешенных проблем. Во-первых, процесс донастройки часто ограничен небольшими наборами данных, что может привести к слишком специализированной модели и уменьшению ее умения рассуждать и производительности на языковых бенчмарках. Во-вторых, попытка максимизировать неполную модель вознаграждения может привести к проблемам, поскольку LLM может находить способы использовать недостатки модели вознаграждения. Наконец, RLHF может снизить разнообразие выводов, приводя к тому, что модель перестает производить разнообразные ответы.
Объединение моделей и их выгоды
Метод объединения весов (WA) позволяет улучшить обобщение путем уменьшения дисперсии, запоминания и выравнивания потерь. Кроме того, объединение весов объединяет их сильные стороны, что полезно в настройках с множественными задачами.
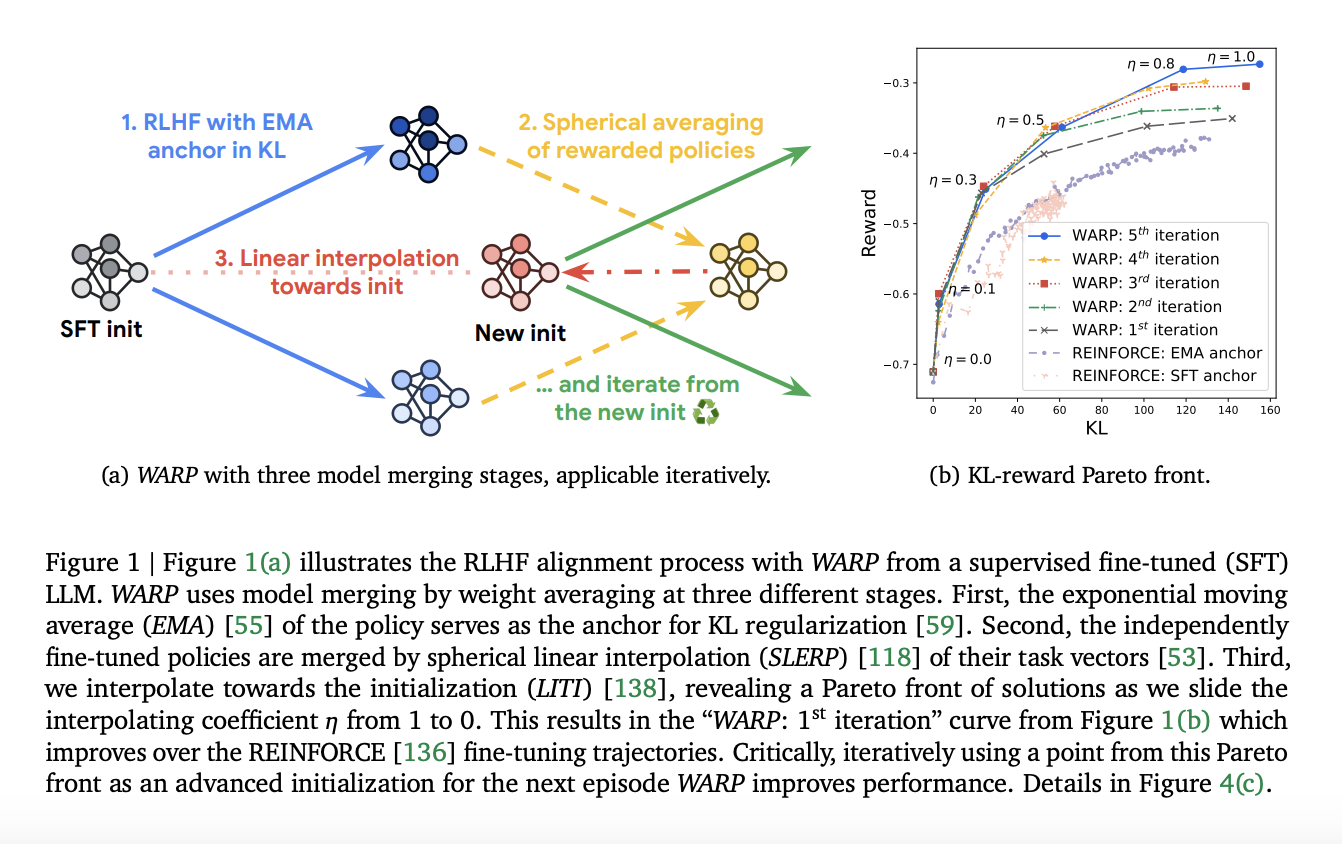
Weight Averaged Rewarded Policies (WARP)
Команда из Google DeepMind предложила метод WARP, который использует три типа WA на трех этапах процесса выравнивания для различных целей. WARP повышает эффективность, как показывают результаты эксперимента, где предложенные политики предпочитались над вариантами Mistral и превосходили предыдущие релизы Gemma «7B».
Заключение
WARP – это новый метод RLHF для оптимизации KL-наградного фронта решений и выравнивания LLMs, который показывает превосходство над современными методами. Он способствует созданию безопасных и мощных систем ИИ путем улучшения выравнивания и поощрения дальнейшего изучения методов объединения моделей.
«`

























