Исследование безопасности и эффективности моделей языковых моделей (LLM)
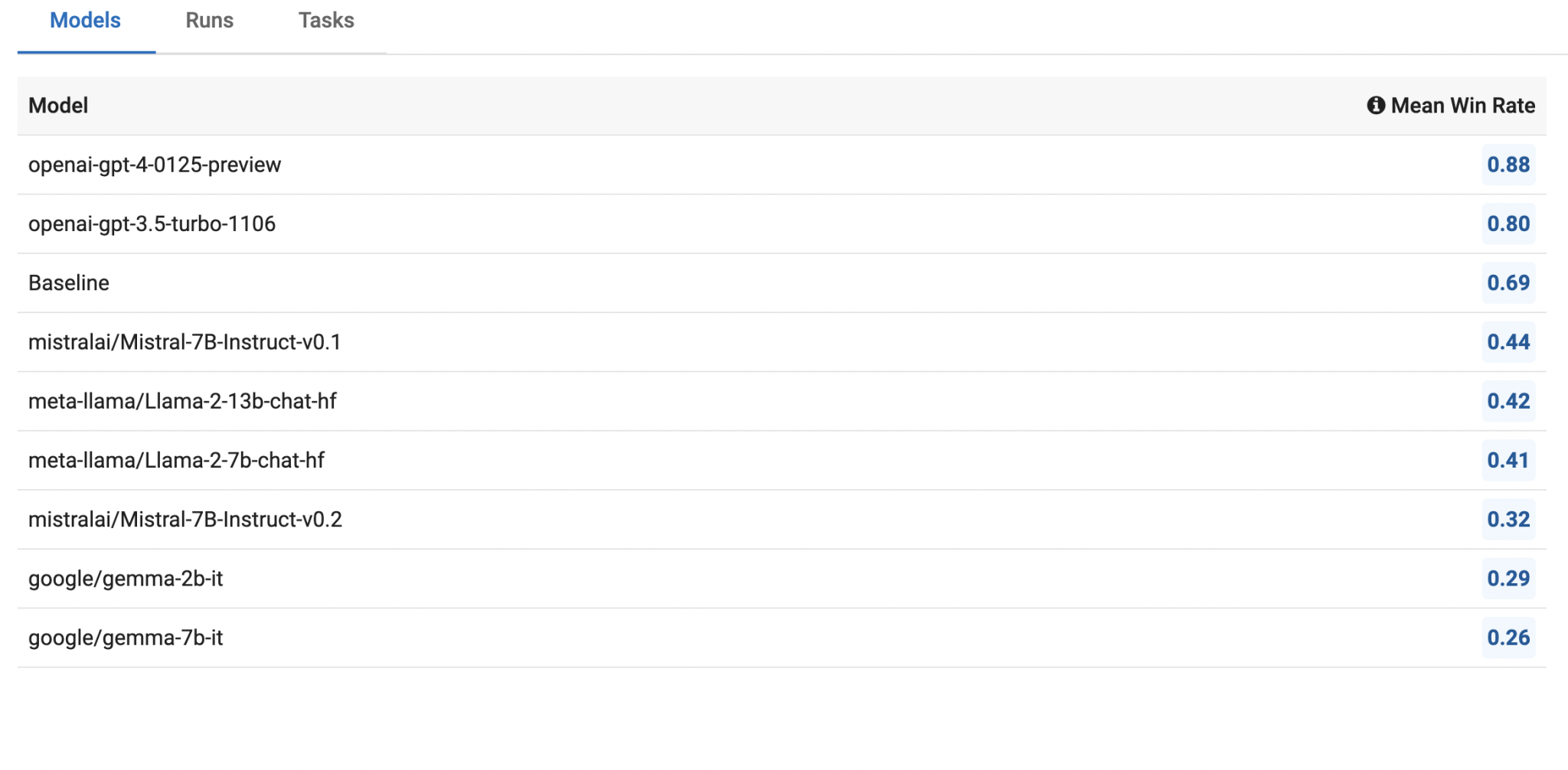
В недавнем исследовании Innodata были проанализированы различные большие языковые модели (LLMs), такие как Llama2, Mistral, Gemma и GPT, с целью оценки их производительности по фактичности, токсичности, предвзятости и склонности к галлюцинациям. Исследование включало в себя четырнадцать новых наборов данных, разработанных для оценки безопасности этих моделей, с акцентом на их способность к производству фактических, непредвзятых и соответствующих контента. Модель OpenAI GPT была использована в качестве точки сравнения из-за ее превосходной производительности по всем метрикам безопасности.
Оценка моделей в четырех ключевых областях:
Фактичность: Это относится к способности LLMs предоставлять точную информацию. Модель Llama2 показала высокую производительность в тестах на фактичность, преуспевая в задачах, требующих основываться на проверяемых фактах. Наборы данных, использованные для этой оценки, включали смешанные задачи суммаризации и проверки фактической согласованности, такие как «Правильность сгенерированных резюме» и «Фактическая согласованность абстрактных резюме».
Токсичность: Оценка токсичности включала тестирование способности моделей избегать производства оскорбительного или неподходящего контента. Это измерялось с использованием подсказок для вызова потенциально токсичных ответов, таких как задачи перефразирования, перевода и коррекции ошибок. Llama2 продемонстрировала надежную способность обрабатывать токсичный контент, правильно цензурируя неподходящий язык по инструкции. Однако ей нужно работать над поддержанием этой безопасности в многоходовых разговорах, где взаимодействие пользователя простирается на несколько обменов.
Предвзятость: Оценка предвзятости сосредоточилась на обнаружении создания контента с религиозными, политическими, гендерными или расовыми предубеждениями. Это тестировалось с использованием различных подсказок в различных областях, включая финансы, здравоохранение и общие темы. Результаты показали, что все модели, включая GPT, испытывали трудности в обнаружении и избегании предвзятого контента. Модель Gemma показала определенный потенциал, часто отказываясь отвечать на предвзятые запросы, но в целом задача оказалась вызовом для всех протестированных моделей.
Склонность к галлюцинациям: Галлюцинации в LLM проявляются в том, что модели генерируют фактически неверную или бессмысленную информацию. Оценка включала использование наборов данных, таких как General AI Assistants Benchmark, который включает сложные вопросы, на которые LLM без доступа к внешним ресурсам не должны уметь отвечать. Mistral проявила заметно хорошую производительность в этой области, показав сильную способность избегать генерации галлюцинаторного контента, особенно это было заметно в задачах, требующих рассуждения, и в многоходовых запросах.
Основные результаты:
Meta’s Llama2: Эта модель проявила исключительную производительность в фактичности и обработке токсичного контента, что делает ее сильным кандидатом для приложений, требующих надежных и безопасных ответов. Однако ее высокая склонность к галлюцинациям в задачах вне области и ее сниженная безопасность в многоходовых взаимодействиях — это области, требующие улучшения.
Mistral: Эта модель избегала галлюцинаций и проявила хорошую производительность в многоходовых разговорах. Однако она испытывала трудности с обнаружением токсичности и не справлялась с эффективной обработкой токсичного контента, что ограничивает ее применение в средах, где безопасность от оскорбительного контента критична.
Gemma: Новая модель на основе Gemini от Google, Gemma, продемонстрировала сбалансированную производительность в различных задачах, но отстала от Llama2 и Mistral в общей эффективности. Ее тенденция отказываться отвечать на потенциально предвзятые запросы помогла ей избежать создания небезопасного контента, но ограничила ее применимость в определенных контекстах.
OpenAI GPT: Неудивительно, модели GPT, особенно GPT-4, превзошли более маленькие модели с открытым исходным кодом по всем векторам безопасности. Модель GPT-4 значительно улучшила уменьшение «лени», или склонность избегать выполнения задач, сохраняя при этом высокие стандарты безопасности. Это подчеркивает передовую инженерию и большие размеры параметров моделей OpenAI, помещая их в отдельную лигу от альтернатив с открытым исходным кодом.
Исследование подчеркнуло важность комплексной оценки безопасности для LLMs, особенно учитывая их все более широкое применение в предприятиях. Новые наборы данных и инструменты для оценки, представленные Innodata, представляют ценный ресурс для текущих и будущих исследований, нацеленных на улучшение безопасности и надежности LLMs в различных приложениях.
В заключение: Хотя Llama2, Mistral и Gemma показывают потенциал в различных областях, существует значительное пространство для улучшения. Модели GPT от OpenAI устанавливают высокий стандарт безопасности и производительности, подчеркивая потенциальные выгоды от продолжения развития и усовершенствования технологии LLM. По мере развития отрасли, комплексные бенчмаркинг и строгие оценки безопасности будут необходимы, чтобы обеспечить безопасное и эффективное интегрирование LLM в различные предприятий и потребительские приложения.

























