«`html
Generalizable Reward Model (GRM): An Efficient AI Approach to Improve the Generalizability and Robustness of Reward Learning for LLMs
Предобученные большие модели показали впечатляющие способности во многих различных областях. Недавние исследования сосредотачиваются на обеспечении соответствия этих моделей человеческим ценностям и предотвращении вредных поведенческих моделей. Для достижения этой цели критически важны методы выравнивания, где два основных метода — это надзорная донастройка (SFT) и обучение с подкреплением на основе обратной связи от человека (RLHF). RLHF полезен для обобщения модели вознаграждения на новые пары запрос-ответ. Однако он сталкивается с проблемой обучения модели вознаграждения, которая хорошо работает с невидимыми данными. Одной из распространенных проблем является «переоптимизация» или «взлом вознаграждения». Увеличение размера модели вознаграждения и объема обучающих данных может помочь решить эту проблему, но это не практично в реальных ситуациях.
Методы выравнивания
Эта статья обсуждает два подхода в связанной работе. Первый подход — моделирование вознаграждения, где модели вознаграждения обучаются на данных о предпочтениях человека для направления процесса RLHF или оптимизации запроса. Недавние исследования сосредотачиваются на разработке лучших моделей вознаграждения для улучшения производительности больших языковых моделей (LLM) в RLHF. Это включает улучшение моделирования вознаграждения путем улучшения качества или количества данных о предпочтениях. Второй подход — смягчение переоптимизации в RLHF, где модели вознаграждения часто переобучаются и испытывают трудности с обобщением за пределы обучающих данных, что приводит к проблеме переоптимизации. Можно наказывать слишком уверенные выходы модели, используя сглаживание меток или регуляризацию SFT для уменьшения этой проблемы.
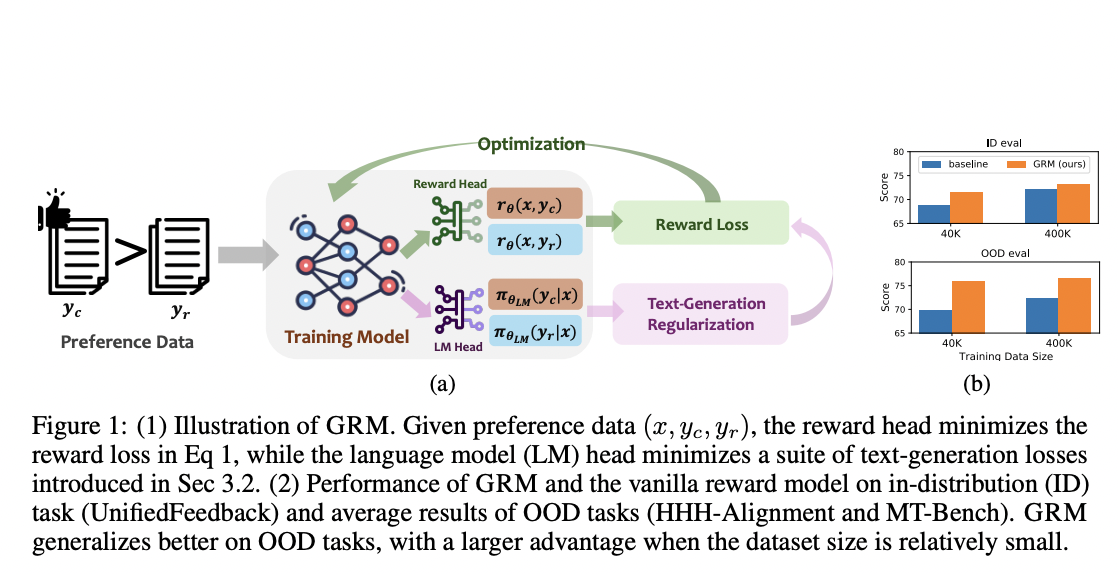
Исследователи из HKUST, Georgia Institute of Technology и University of Illinois Urbana-Champaign представили Generalizable Reward Model (GRM), который использует регуляризацию генерации текста на скрытые состояния для улучшения производительности моделей вознаграждения. Их исследование показывает, что все три типа регуляризации генерации текста хорошо работают с GRM, при этом регуляризация SFT является наиболее эффективным и надежным решением. Результаты демонстрируют, что GRM значительно улучшает точность моделей вознаграждения в различных задачах вне распределения (OOD). Более того, он последовательно повышает производительность RLHF и помогает уменьшить проблему переоптимизации.
Для обучения моделей вознаграждения используется Unified-Feedback dataset, который является одним из крупнейших наборов парных наборов данных обратной связи. Все модели вознаграждения обучаются на подмножестве из 400 тыс. и 40 тыс. экземпляров из Unified-Feedback dataset и оцениваются на 8 тыс. экземпляров hold-out eval set. Более того, при оценке производительности модели на предпочтительных данных вне распределения используются наборы данных, такие как HHH-Alignment, MT-Bench Human Judgements и RewardBench. Набор данных HHH-Alignment оценивает языковые модели на полезность, честность и безвредность, в то время как набор данных MT-Bench содержит предпочтения человека для ответов модели на вопросы MT-bench.
Результаты GRM
GRM значительно улучшает способность моделей вознаграждения к обобщению, приводя к лучшей производительности как на внутрираспределенных (ID), так и на вне распределения (OOD) наборах оценки.
Все три типа потерь регуляризации генерации текста могут улучшить обобщение, причем регуляризация SFT является наиболее эффективным и последовательным.
Он показывает сильную производительность даже с ограниченными наборами данных, превосходя базовые значения с большим отрывом.
GRM эффективно уменьшает проблему переоптимизации в BoN и PPO и устойчив к помехам меток в данных о предпочтениях.
В заключение, исследователи предложили Generalizable Reward Model (GRM), эффективный метод, направленный на улучшение обобщаемости и устойчивости обучения на вознаграждение для LLM. GRM использует техники регуляризации на скрытых состояниях моделей вознаграждения, что значительно улучшает способность моделей к обобщению на невидимые данные. Более того, предложенный подход эффективно уменьшает проблему переоптимизации в RLHF. Эти результаты поддержат будущие исследования по созданию более сильных моделей вознаграждения, помогая более эффективно выравнивать большие модели и обеспечивать решения с оптимальным соотношением цены и качества.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу 46 тыс. подписчиков в ML SubReddit.
Попробуйте ИИ ассистент в продажах здесь. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.