«`html
Оптимизация крупных языковых моделей (LLM) на процессорах: техники для улучшения вывода и эффективности
Крупные языковые модели (LLM), основанные на архитектуре Transformer, недавно достигли важных технологических достижений. Их замечательные навыки в понимании и создании текстов, напоминающих человеческие, оказали значительное влияние на различные приложения искусственного интеллекта (ИИ). Однако существует множество препятствий для успешной реализации этих моделей в условиях ограниченных ресурсов. Особое внимание промышленность уделяет этой проблеме в ситуациях, когда доступ к аппаратным ресурсам GPU ограничен. В таких случаях становятся важными альтернативы на основе ЦПУ.
Улучшение производительности вывода
Улучшение производительности вывода на процессорах критично для снижения издержек и преодоления ограничений ресурсов аппаратного обеспечения. В недавних исследованиях команда ученых представила простой вариант, который улучшает производительность вывода LLM на ЦПУ. Основной особенностью этого решения является практический способ уменьшения размера кеша KV без ущерба точности. Данная оптимизация необходима для обеспечения эффективной работы LLM, даже при ограниченных ресурсах.
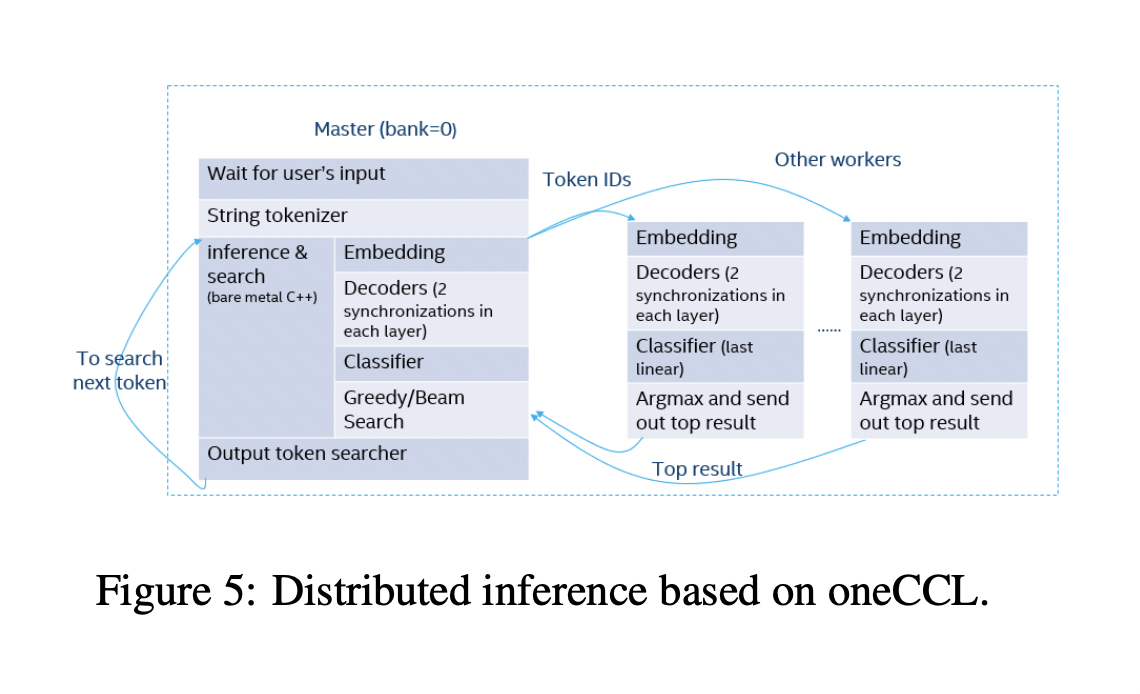
Оптимизация распределенного вывода
Исследование также предложило технику оптимизации распределенного вывода, использующую библиотеку коллективных связей oneAPI. Этот метод значительно повышает масштабируемость и производительность LLM путем обеспечения эффективной коммуникации и обработки между различными ЦПУ. Кроме того, предусмотрены индивидуальные оптимизации для наиболее популярных моделей, что гарантирует гибкость и пригодность решения для различных LLM. Целью внедрения этих оптимизаций является ускорение работы LLM на ЦПУ, что увеличит их доступность для использования в условиях ограниченных ресурсов.
Команда суммировала свои основные вклады следующим образом:
- Предоставление уникальных методов оптимизации LLM на ЦПУ, таких как SlimAttention, совместимых с популярными моделями Qwen, Llama, ChatGLM, Baichuan и серией Opt, а также представляющих собой индивидуальные оптимизации для процедур и слоев LLM.
- Предложение работоспособной стратегии уменьшения размера кеша KV без ущерба точности. Этот метод повышает эффективность использования памяти без значительного ухудшения качества выходных данных модели.
- Разработка специально для LLM на ЦПУ методики оптимизации распределенного вывода, подходящей для масштабных приложений, поскольку обеспечивает масштабируемость и эффективность вывода с низкой задержкой.
Подробности исследования и код находятся на GitHub. Вся заслуга за это исследование принадлежит ученым этого проекта.
Применение ИИ в бизнесе
Если вы хотите использовать ИИ для развития своей компании, обратитесь к нам. Мы предлагаем консультации по внедрению ИИ и помогаем определить области применения автоматизации, где ваши клиенты могут выиграть от использования ИИ. Мы также поможем выбрать подходящее решение из множества доступных на рынке вариантов ИИ. Начните внедрение с небольшого проекта, а затем постепенно расширяйте применение ИИ, основываясь на полученных данных и опыте.
Если вам интересно узнать больше о внедрении ИИ, пишите нам на наш канал в Telegram.
Мы также предлагаем использование ИИ-ассистента в продажах, который помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.
«`

























