Использование языковых моделей в искусственном интеллекте
Языковые модели (LMs) стали фундаментальными в обработке естественного языка (NLP), позволяя генерацию текста, перевод и анализ тональности. Однако для точной и эффективной работы эти модели требуют огромного объема тренировочных данных. Качество и курирование этих наборов данных критически влияют на производительность LMs. Эта область фокусируется на улучшение методов сбора и подготовки данных для повышения эффективности моделей.
Проблемы и решения
Одной из ключевых проблем в разработке эффективных языковых моделей является улучшение тренировочных наборов данных. Высококачественные наборы данных необходимы для обучения моделей, которые обобщают задачи, однако создание таких наборов данных сложно. Это включает фильтрацию нерелевантного или вредоносного контента, удаление дубликатов и выбор наиболее полезных источников данных.
Существующие методы курирования наборов данных обычно включают в себя фильтрацию на основе эвристик, удаление дубликатов и сбор данных из обширных веб-краулеров. Хотя эти методы имеют некоторый успех, часто требуются более стандартизированные показатели, что приводит к согласованности при оценке производительности языковых моделей. Эта изменчивость затрудняет определение наиболее эффективных стратегий курирования данных, что затрудняет прогресс в этой области.
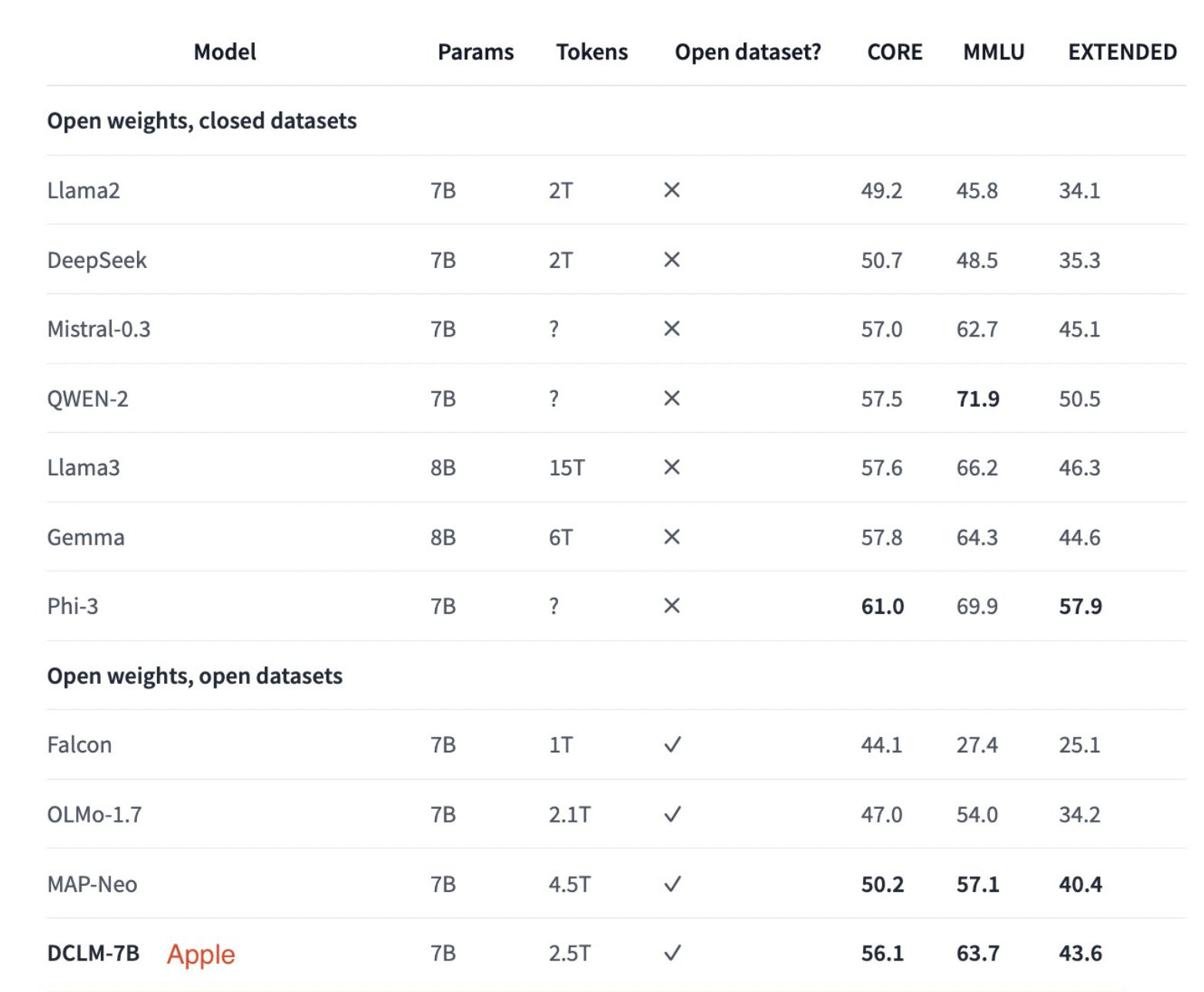
Ученые из Apple, University of Washington и других учреждений представили DataComp for Language Models (DCLM) для решения этих проблем. Они недавно опубликовали модели DCIM и наборы данных на платформе Hugging Face. Релиз включает DCLM-7B, DCLM-1B, dclm-7b-it, DCLM-7B-8k, dclm-baseline-1.0 и dclm-baseline-1.0-parquet. Этот инновационный тестовый стенд позволяет проводить контролируемые эксперименты с большими наборами данных для улучшения языковых моделей. DCLM предоставляет структурированный рабочий процесс для исследователей, позволяя проводить эксперименты с курированием данных и тестировать их производительность на различных задачах.
Эффективность и потенциал
Внедрение DCLM привело к значительным улучшениям в обучении языковых моделей. Например, базовый набор данных, созданный с использованием DCLM, позволил обучить языковую модель с 7 миллиардами параметров с нуля. Эта модель достигла 64% точности на бенчмарке MMLU с 2.6 триллионами тренировочных токенов. Эта производительность представляет собой улучшение на 6.6 процентных пункта по сравнению с предыдущей передовой языковой моделью с открытыми данными, MAP-Neo, используя 40% меньше вычислительных ресурсов.
Эффективность DCLM подтверждается ее масштабируемостью. Исследователи проводили эксперименты на различных масштабах, от 400M до более чем 7B параметров, используя DCLM-Pool, корпус из 240 триллионов токенов из Common Crawl. Эти эксперименты подчеркнули важную роль модельной фильтрации в сборке высококачественных тренировочных наборов данных. Базовый набор данных DCLM, созданный через этот тщательный процесс, последовательно превзошел другие наборы данных с открытым исходным кодом в различных оценках.
Команда исследователей также исследовала влияние различных техник курирования данных. Они сравнили методы извлечения текста, такие как resiliparse и trafilatura, и обнаружили, что эти подходы значительно улучшают производительность по сравнению с предварительно извлеченным текстом Common Crawl. Они также провели исследования модельных методов фильтрации качества и установили, что классификатор fastText OH-2.5 + ELI5 является наиболее эффективным, обеспечивая существенный прирост в точности.
Заключение
Введение DCLM позволяет исследователям проводить контролируемые эксперименты и выявлять наиболее эффективные стратегии для улучшения языковых моделей, предоставляя стандартизированный и систематический подход к курированию наборов данных. DCLM устанавливает новые стандарты качества наборов данных и демонстрирует потенциал для значительного улучшения производительности с уменьшением вычислительных ресурсов.

























