«`html
Новый метод оценки точности выполнения задач Retrieval-Augmented Large Language Models (RAG)
Большие языковые модели (LLM) стали значительно популярны в последнее время. Однако оценка LLM по широкому спектру задач может быть крайне сложной. Общедоступные стандарты не всегда точно отражают общие навыки LLM, особенно когда речь идет о выполнении высокоспециализированных задач для клиентов, требующих специфических знаний в определенной области. Для оценки правильности систем Retrieval-Augmented Generation (RAG) на конкретных задачах команда исследователей из Amazon предложила подход к оценке на основе экзаменов, усиленный LLM. Для этой полностью автоматизированной процедуры не требуется заранее аннотированный набор данных. Основное внимание уделяется фактической точности или способности системы получать и применять правильные данные для точного ответа на запрос пользователя. Этот метод предоставляет пользователям более глубокие понимание факторов, влияющих на производительность RAG, включая размер модели, механизмы извлечения, техники подсказок и процедуры настройки, помогая им выбрать оптимальное сочетание компонентов для своих систем RAG.
Автоматизированный подход к оценке
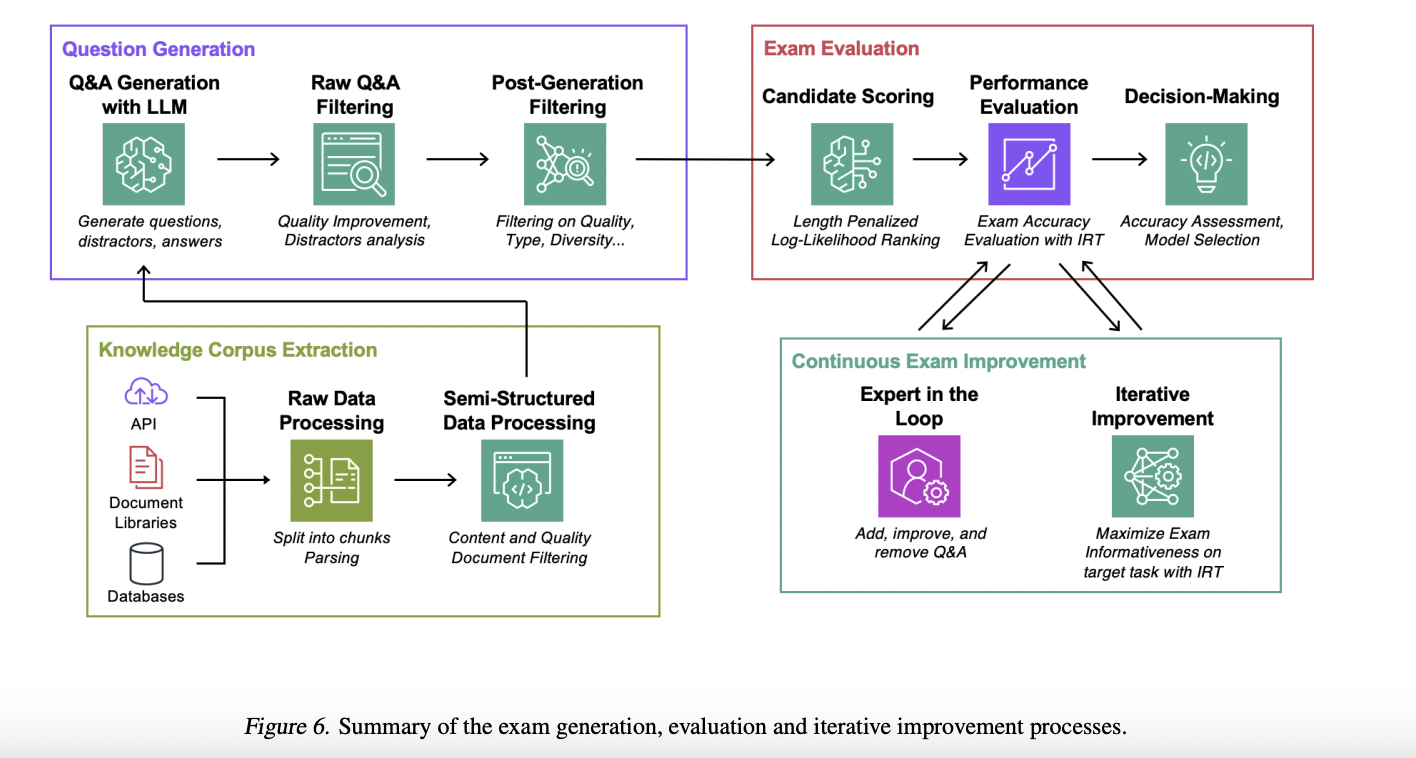
Команда предложила полностью автоматизированный, количественный подход к оценке на основе экзаменов, который можно масштабировать. В отличие от традиционных оценок с участием человека, которые могут быть дорогостоящими из-за необходимости участия эксперта или аннотатора, экзамены создаются с использованием этого метода LLM, использующего корпус данных, связанных с текущим заданием. Затем кандидатские системы RAG оцениваются согласно их способности отвечать на тесты с выбором ответов, взятые из этих оценок.
Методологическое усовершенствование
В частности, с использованием теории ответов на элементы (IRT) создаются надежные и понятные метрики оценки. Эти метрики помогают количественно оценивать и разъяснять аспекты, влияющие на эффективность модели. Также был предложен методичный полностью автоматизированный подход к созданию тестов, использующий итерационный процесс улучшения для оптимизации информативности экзаменов, обеспечивая точную оценку возможностей модели.
Основные вклады команды
Команда предоставила широкий подход к автоматической оценке конвейеров Retrieval-Augmented Generation (RAG) LLM на основе синтетических тестов, специфичных для задач и созданных для удовлетворения уникальных требований каждого задания. Использование теории ответов на элементы (IRT) для создания надежных и понятных метрик оценки. Предоставление бенчмарк-наборов данных для оценки систем RAG на основе четырех уникальных задач.
Применение ИИ в бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте новые методы оценки точности выполнения задач Retrieval-Augmented Large Language Models (RAG). Проанализируйте, как ИИ может изменить вашу работу, определите, где возможно применение автоматизации и определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ. Подберите подходящее решение, внедряйте ИИ решения постепенно, начиная с малого проекта, и расширяйте автоматизацию на основе полученных данных и опыта.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Попробуйте ИИ ассистент в продажах здесь. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.
«`

























