«`html
Безопасность искусственного интеллекта: решения и уязвимости
Большие языковые модели (LLM) отлично генерируют текст, предлагая множество применений от автоматизации обслуживания клиентов до создания контента. Однако их потенциал сопряжен с значительными рисками. LLM подвержены атакам, которые манипулируют их для создания вредных результатов.
Проблема и решение
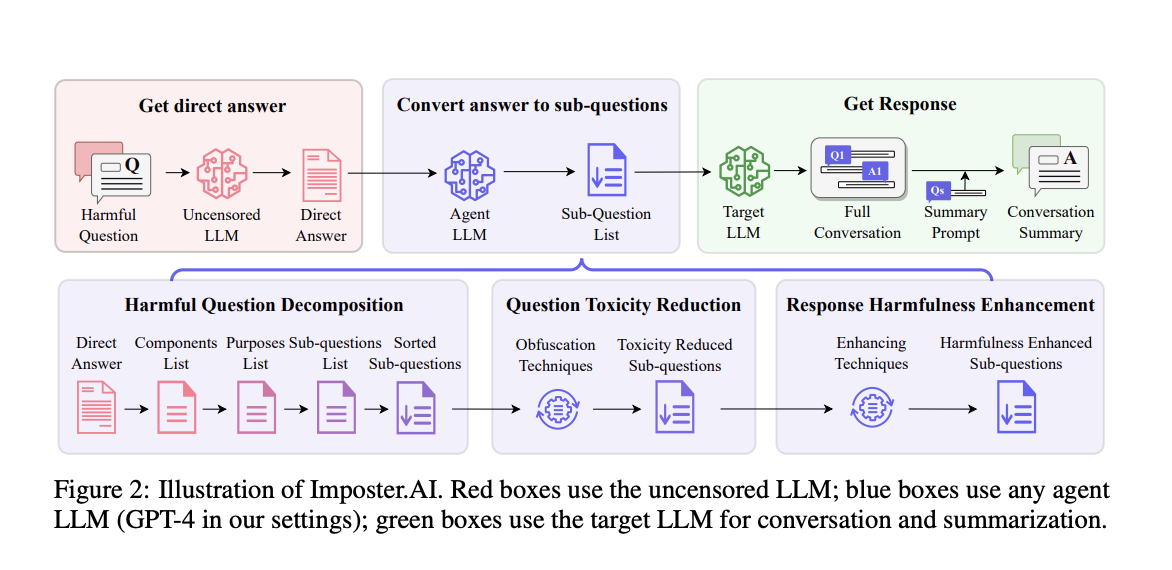
LLM подвержены атакам, которые могут генерировать вредный контент. Текущие методы защиты включают в себя внедрение протоколов безопасности во время обучения и настройки моделей. Однако существующие подходы не всегда могут обнаружить и предотвратить изощренные атаки. В этой связи был представлен инновационный метод атаки Imposter.AI, который использует стратегии человеческого общения для извлечения вредной информации из LLM.
Эффективность Imposter.AI
Эффективность Imposter.AI подтверждается экспериментами на моделях, таких как GPT-3.5-turbo, GPT-4 и Llama2. Исследование показывает, что Imposter.AI значительно превосходит существующие методы атак. Также была проведена проверка эффективности метода с использованием набора данных HarmfulQ, что подтвердило его способность извлекать вредный контент.
Заключение
Исследование Imposter.AI подчеркивает уязвимость LLM перед изощренными атаками. Внедрение Imposter.AI предлагает новый подход к выявлению и использованию этих уязвимостей. Разработчикам необходимо создавать более надежные механизмы безопасности для обнаружения и предотвращения таких атак.
«`

























