«`html
MINT-1T Dataset: новый этап в развитии искусственного интеллекта
Искусственный интеллект, особенно при обучении больших мультимодальных моделей (LMM), сильно полагается на обширные наборы данных, включающие последовательности изображений и текста. Эти наборы данных позволяют разрабатывать сложные модели, способные понимать и генерировать мультимодальный контент. По мере усовершенствования возможностей ИИ-моделей возрастает потребность в обширных и качественных наборах данных, что стимулирует исследователей искать новые методы сбора и курирования данных.
Создание MINT-1T
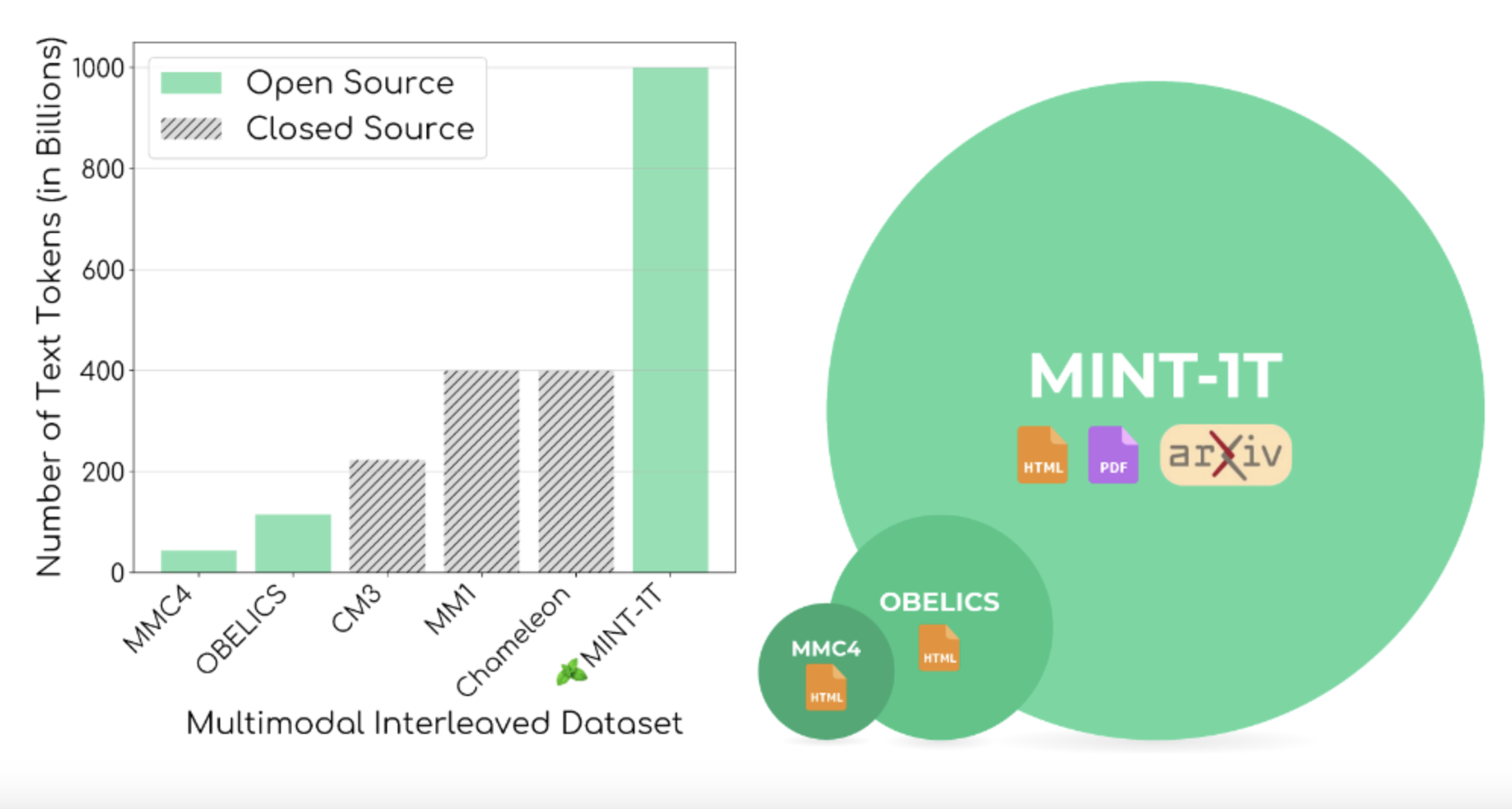
Ученые из University of Washington, Salesforce Research, Stanford University, University of Texas at Austin и University of California Berkeley представили MINT-1T, самый обширный и разнообразный открытый мультимодальный набор данных на сегодняшний день. MINT-1T включает один триллион токенов текста и 3,4 миллиарда изображений из HTML, PDF-файлов и научных статей ArXiv. Этот набор данных представляет собой увеличение в десять раз по сравнению с предыдущими наборами данных, что значительно улучшает данные для обучения мультимодальных моделей.
Практическое применение
Эксперименты показали, что LMM, обученные на наборе данных MINT-1T, соответствуют и часто превосходят производительность моделей, обученных на предыдущих ведущих наборах данных, таких как OBELICS. Включение более разнообразных источников в MINT-1T привело к лучшей обобщенности и производительности в различных бенчмарках. Набор данных значительно улучшил производительность в задачах визуального ответа на вопросы и мультимодального рассуждения. Ученые обнаружили, что модели, обученные на MINT-1T, показали лучшие результаты на нескольких демонстрациях, подчеркивая эффективность набора данных.
Вывод
Набор данных MINT-1T решает проблему недостатка и разнообразия наборов данных. Представляя более крупный и разнообразный набор данных, ученые обеспечили разработку более надежных и производительных открытых мультимодальных моделей. Эта работа подчеркивает важность разнообразия и масштаба данных в исследованиях ИИ и прокладывает путь для будущих улучшений и применений в мультимодальном ИИ.
«`

























