«`html
Оценка причинно-следственных связей с помощью нейронных сетей
Оценка причинно-следственных связей является важной для понимания влияния вмешательств в различных областях, таких как здравоохранение, социальные науки и экономика. Традиционные методы часто включают обширный сбор данных и структурированные эксперименты, что может быть затратным и занимать много времени.
Проблема структурированных данных
Необходимость структурированных данных и ручной кураторства данных затрудняет текущие подходы к оценке причинно-следственных связей. Это увеличивает затраты и время исследований, а также ограничивает объем данных, которые можно проанализировать. Неструктурированные данные, такие как естественный язык из социальных медиа или форумов, представляют собой богатый, но недостаточно используемый источник информации для причинного анализа.
Решение: NATURAL
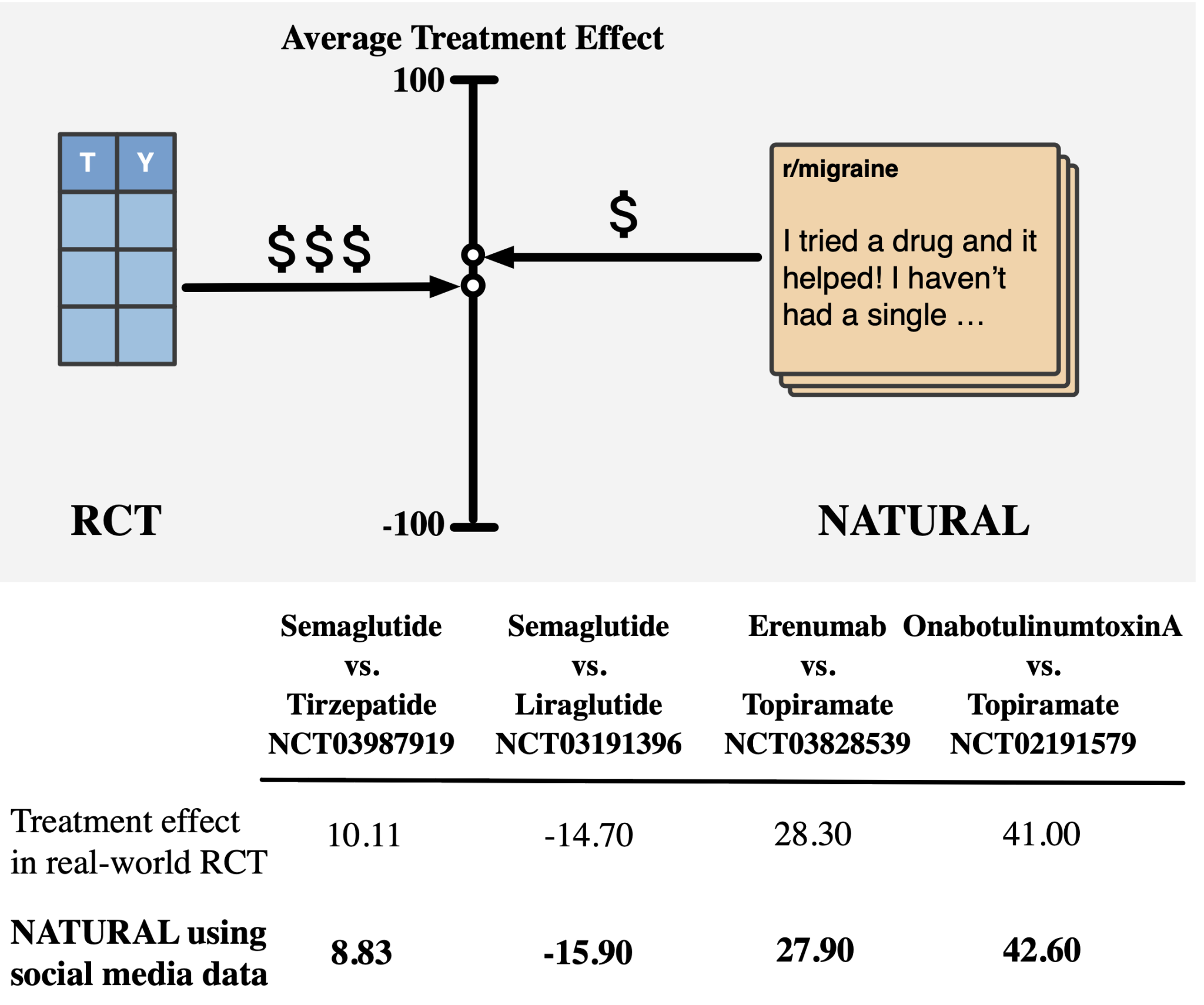
Исследователи из Университета Торонто, Института Вектор и Meta AI представили NATURAL, новую семейство оценщиков причинно-следственных связей, использующих большие языковые модели (LLM) для анализа неструктурированных текстовых данных. Метод позволяет извлекать причинную информацию из различных источников, таких как сообщения в социальных сетях, клинические отчеты и форумы пациентов. Автоматизация кураторства данных и использование возможностей LLM делает NATURAL масштабируемым решением для различных приложений.
Процесс NATURAL
NATURAL использует LLM для обработки текстов на естественном языке и оценки условных распределений интересующих переменных. Процесс включает в себя фильтрацию отчетов, извлечение ковариатов и обработок, а также использование их для вычисления средних эффектов лечения (ATE). Методика имитирует традиционные методы причинного вывода, но работает с неструктурированными данными, что делает ее универсальным и масштабируемым решением.
Результаты и преимущества
Предложенные оценщики NATURAL продемонстрировали высокую точность, с оценками ATE, соответствующими реальным значениям на три процентных пункта в экспериментах с рандомизированными данными. Метод успешно применялся к шести наборам данных, включая синтетические и реальные клинические данные. Например, для набора данных Semaglutide vs. Tirzepatide NATURAL точно предсказывал результаты по снижению веса средней абсолютной ошибкой в 2,5%. Метод также продемонстрировал надежную производительность в предсказании результатов для лечения диабета и мигрени, достигая высокой согласованности с результатами клинических испытаний. При этом стоимость вычислительного анализа значительно снизилась, составив всего несколько сотен долларов по сравнению с традиционными методами.
Потенциал и применение
Способность NATURAL точно оценивать причинные эффекты из неструктурированных данных предполагает трансформационный потенциал для областей, сильно зависящих от причинного анализа. Путем использования свободно доступных текстовых данных этот метод может значительно сократить время и затраты, связанные с традиционными методами оценки причинных эффектов. Подход особенно ценен для приложений, где рандомизированные исследования невозможны или слишком дороги.
Заключение
Фреймворк NATURAL представляет собой новаторский подход к оценке причинно-следственных связей с использованием неструктурированных данных на естественном языке. Автоматизация кураторства данных и использование LLM предоставляют масштабируемое решение, которое может революционизировать области, зависящие от причинного анализа. Этот метод решает текущие ограничения и открывает новые возможности для использования богатых неструктурированных источников данных.
«`
«`html
Как внедрить искусственный интеллект в ваш бизнес
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте технологии, представленные в NATURAL: A Pipeline for Causal Estimation from Unstructured Text Data in Hours, Not Years.
Практические шаги
Проанализируйте, как ИИ может изменить вашу работу и определите, где можно применить автоматизацию, чтобы ваши клиенты извлекли выгоду из этой технологии. Определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ.
Подберите подходящее решение для вашего бизнеса, внедряйте его постепенно, начиная с малого проекта, и анализируйте результаты. На основе полученных данных и опыта расширяйте автоматизацию.
Получите поддержку и консультации
Если вам нужны советы по внедрению ИИ, обращайтесь к нам. Мы поможем вам с внедрением технологий искусственного интеллекта в ваш бизнес.
Попробуйте нашего ИИ ассистента в продажах. Этот инструмент помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как искусственный интеллект может изменить ваши процессы с решениями от Flycode.ru.
«`

























