Новые исследования об искусственном интеллекте
Исследование Stanford предлагает новые идеи по предотвращению коллапса модели и накоплению данных в ИИ
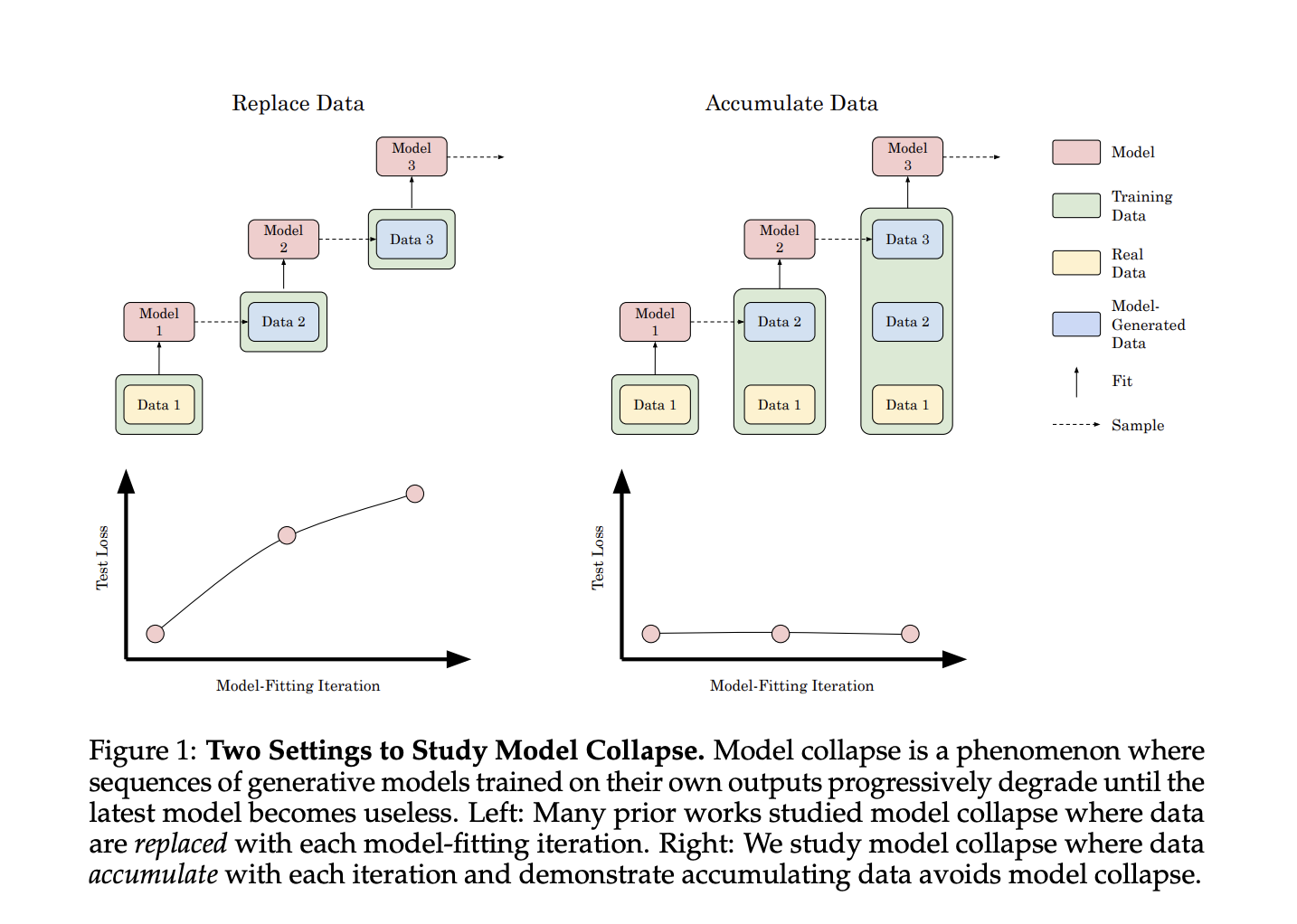
Исследователи из Стэнфордского университета предлагают новое исследование, которое исследует влияние накопления данных на коллапс модели в генеративных моделях искусственного интеллекта. В отличие от предыдущих исследований, сосредоточенных на замене данных, этот подход моделирует непрерывное накопление синтетических данных в интернет-основанных наборах данных. Эксперименты с трансформаторами, моделями диффузии и вариационными автокодировщиками в различных типах данных показывают, что накопление синтетических данных вместе с реальными данными предотвращает коллапс модели, в отличие от наблюдаемого ухудшения производительности при замене данных.
Данное исследование представляет значимость накопления синтетических данных в предотвращении коллапса модели в различных областях искусственного интеллекта, подчеркивая различия в эффективности в зависимости от типа модели и набора данных.
Исследования также показывают, что тренировка на смеси реальных и синтетических данных предотвращает коллапс модели, в отличие от тренировки только на синтетических данных, что может быть важным для предотвращения ухудшения производительности и качества данных при разработке будущих систем искусственного интеллекта.
Подробнее с исследованием можно ознакомиться здесь.

























