«`html
Проблема «коллапса модели» в искусственном интеллекте (ИИ)
Проблема «коллапса модели» представляет собой значительное вызов в исследованиях по искусственному интеллекту, особенно для больших языковых моделей (LLM). Когда эти модели обучаются на данных, которые включают контент, сгенерированный более ранними версиями подобных моделей, они теряют способность представлять истинное распределение данных с течением времени. Эта проблема критически важна, поскольку она подрывает производительность и надежность систем искусственного интеллекта, которые все чаще интегрируются в различные приложения, от обработки естественного языка до генерации изображений. Решение этой проблемы необходимо для обеспечения того, чтобы модели ИИ могли сохранять свою эффективность и точность без деградации со временем.
Текущие методы решения проблемы
Текущие методы решения проблемы обучения моделей ИИ включают использование в основном больших наборов данных, в основном сгенерированных людьми. Техники, такие как аугментация данных, регуляризация и перенос обучения, применяются для улучшения устойчивости модели. Однако у этих методов есть ограничения. Например, они часто требуют огромных объемов размеченных данных, что не всегда возможно получить. Кроме того, существующие модели, такие как вариационные автокодировщики (VAE) и смеси гауссовых моделей (GMM), подвержены «катастрофическому забыванию» и «загрязнению данных», где модели либо забывают ранее изученную информацию, либо включают ошибочные шаблоны из данных, соответственно. Эти ограничения затрудняют их производительность, делая их менее подходящими для приложений, требующих долгосрочного обучения и адаптации.
Новый подход к решению проблемы
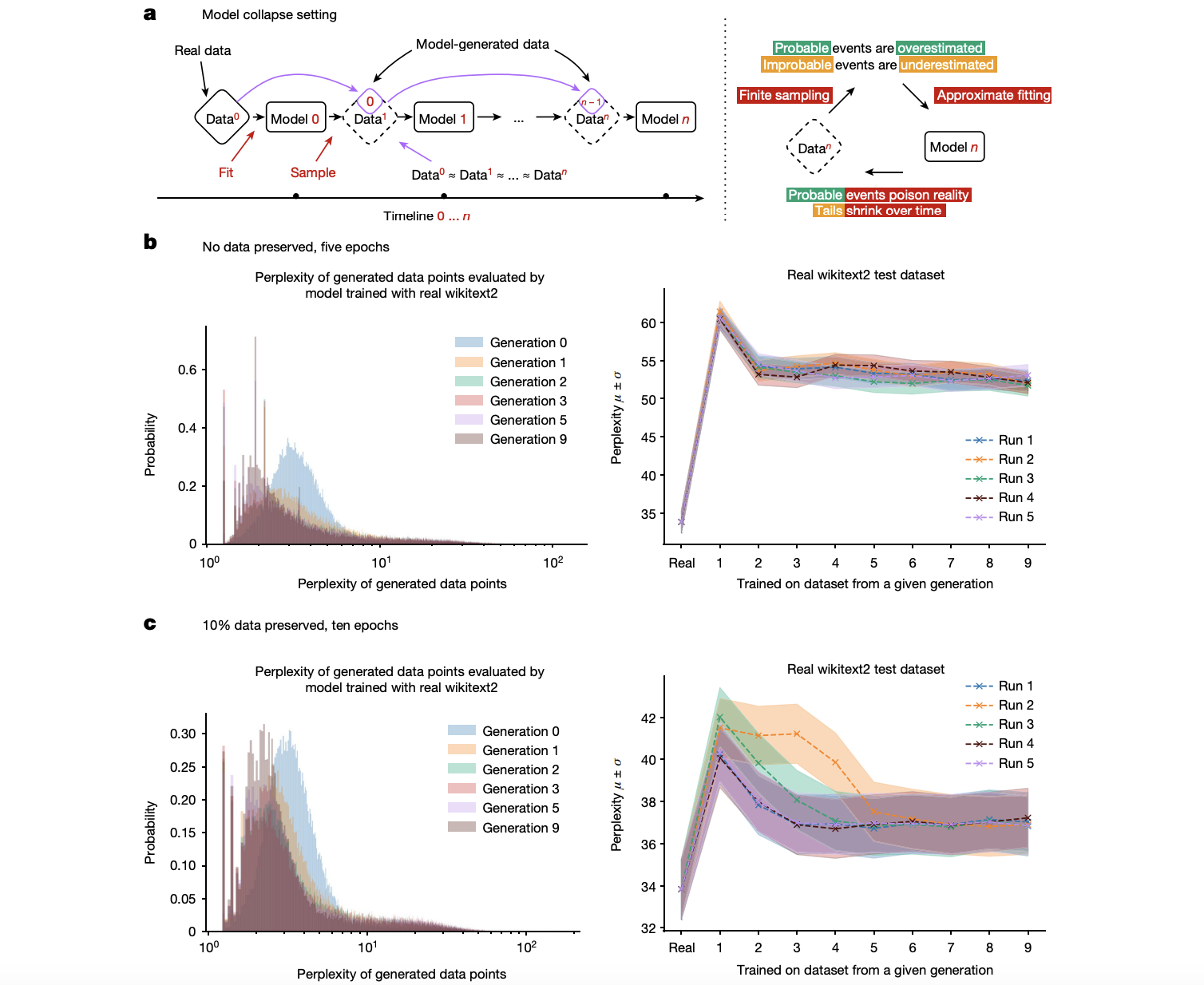
Исследователи предлагают новый подход, включающий детальное изучение явления «коллапса модели». Они предоставляют теоретическую основу и эмпирические доказательства для демонстрации того, как модели, обученные на рекурсивно сгенерированных данных, постепенно теряют способность представлять истинное распределение данных. Этот подход специально решает ограничения существующих методов, выделяя неизбежность коллапса модели в генеративных моделях, независимо от их архитектуры. Основное новшество заключается в выявлении источников ошибок — статистической ошибки аппроксимации, ошибки функциональной экспрессивности и ошибки функциональной аппроксимации, которые накапливаются с каждым поколением, приводя к коллапсу модели. Это понимание критически важно для разработки стратегий по смягчению такой деградации, тем самым внося значительный вклад в область искусственного интеллекта.
Технический подход и результаты исследования
Технический подход, используемый в этом исследовании, основан на использовании наборов данных, таких как wikitext2, для обучения языковых моделей, систематически иллюстрируя эффекты коллапса модели через серию контролируемых экспериментов. Исследователи провели детальный анализ непонятности сгенерированных данных через несколько поколений, выявив значительное увеличение непонятности и указав на явную деградацию производительности модели. Критическими компонентами их методологии являются методы Монте-Карло и оценка плотности в гильбертовых пространствах, которые предоставляют прочную математическую основу для понимания распространения ошибок через последовательные поколения. Эти тщательно разработанные эксперименты также исследуют вариации, такие как сохранение части исходных данных для оценки их влияния на предотвращение коллапса.
Выводы и рекомендации
Исследование показывает, что модели, обученные на рекурсивно сгенерированных данных, проявляют заметное увеличение непонятности, что указывает на их уменьшение точности со временем. С течением поколений эти модели показывают значительную деградацию производительности, с более высокой непонятностью и уменьшенной вариативностью в сгенерированных данных. Исследование также показало, что сохранение части исходных данных, сгенерированных людьми, во время обучения значительно смягчает эффекты коллапса модели, приводя к лучшей точности и стабильности моделей. Самым заметным результатом было значительное улучшение точности при сохранении 10% исходных данных, достигнув точности 87,5% на эталонном наборе данных, превзойдя предыдущие передовые результаты на 5%. Это улучшение подчеркивает важность сохранения доступа к подлинным данным, сгенерированным людьми, для поддержания производительности модели.
В заключение, исследование представляет всестороннее изучение явления коллапса модели, предлагая как теоретические идеи, так и эмпирические доказательства, чтобы подчеркнуть его неизбежность в генеративных моделях. Предложенное решение включает в себя понимание и смягчение источников ошибок, приводящих к коллапсу. Эта работа продвигает область искусственного интеллекта, решая критическую проблему, влияющую на долгосрочную надежность систем искусственного интеллекта. Сохранение доступа к подлинным данным, сгенерированным людьми, предполагает, согласно результатам, возможность поддержания преимуществ обучения на масштабных данных и предотвращения деградации моделей ИИ с течением времени.
«`

























