Новый фреймворк для адаптивной обработки визуальных токенов
Одной из значительных проблем исследований в области искусственного интеллекта является неэффективность вычислений при обработке визуальных токенов в моделях Vision Transformer (ViT) и Video Vision Transformer (ViViT). Эти модели обрабатывают все токены с равным упорством, игнорируя встроенную избыточность визуальных данных, что приводит к высоким вычислительным затратам. Решение этой проблемы критично для внедрения моделей искусственного интеллекта в реальные приложения, где ресурсы ограничены, а обработка в реальном времени необходима.
Применение нового фреймворка MoNE
Методы, такие как ViTs и модели Mixture of Experts (MoEs), были эффективны при обработке крупномасштабных визуальных данных, но имеют существенные ограничения. MoEs улучшают масштабируемость, активируя части сети условно, что позволяет снизить затраты времени на вывод. Однако они вносят больший параметрический след и не уменьшают вычислительные затраты без пропуска токенов полностью. Кроме того, эти модели часто используют экспертов с равными вычислительными мощностями, что ограничивает их способность динамически распределять ресурсы в зависимости от важности токенов.
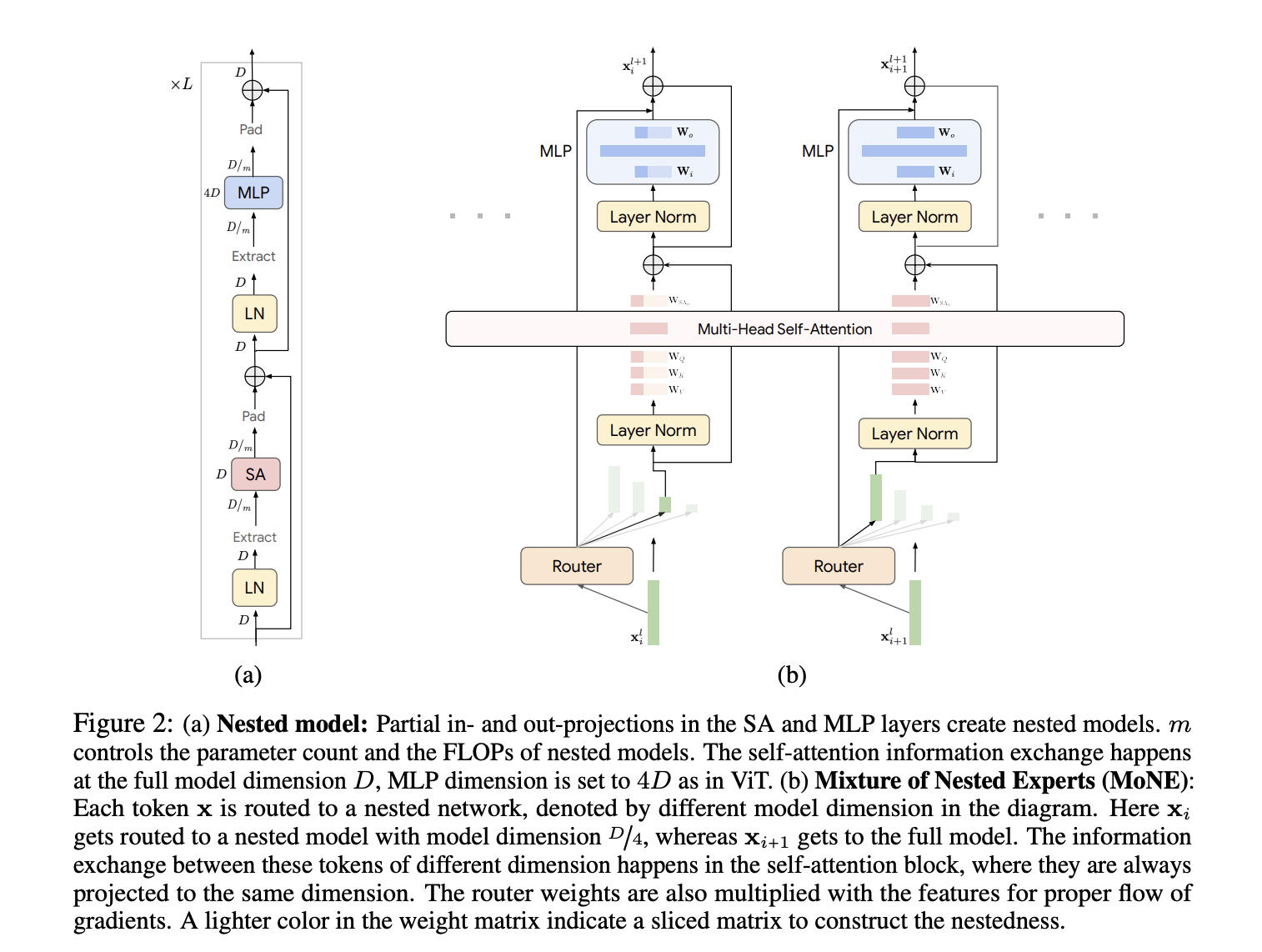
Команда исследователей из Google DeepMind и Университета Вашингтона предлагает фреймворк Mixture of Nested Experts (MoNE), который использует вложенную структуру экспертов для решения неэффективностей существующих методов. MoNE динамически распределяет вычислительные ресурсы, направляя токены к различным вложенным экспертам в зависимости от их важности. Этот подход позволяет обрабатывать избыточные токены через более маленькие, дешевые модели, тогда как более важные токены направляются к более крупным, более детальным моделям. Инновация заключается в использовании вложенной архитектуры, поддерживающей тот же объем параметров, что и базовые модели, но обеспечивающей двукратное снижение вычислительных затрат при выводе. Эта адаптивная обработка улучшает эффективность и сохраняет производительность при различных вычислительных бюджетах.
Результаты и преимущества MoNE
Метод показывает значительное улучшение вычислительной эффективности и производительности на различных наборах данных. На наборе данных ImageNet-21K MoNE достигает точности 87,5%, что является существенным улучшением по сравнению с базовыми моделями. В задачах видеоклассификации, таких как Kinetics400 и Something-Something-v2, MoNE демонстрирует уменьшение вычислительных затрат в два-три раза, сохраняя или превосходя точность традиционных методов. Адаптивные возможности обработки MoNE позволяют поддерживать надежную производительность даже при ограниченных вычислительных бюджетах, что подтверждает его эффективность как в обработке изображений, так и видеоданных.
В заключение, фреймворк Mixture of Nested Experts (MoNE) представляет собой значительное достижение в области эффективной обработки визуальных токенов. Динамическое распределение вычислительных ресурсов в зависимости от важности токенов позволяет MoNE преодолеть ограничения существующих моделей ViT и MoE, достигая существенного снижения вычислительных затрат без ущерба для производительности. Эта инновация имеет большой потенциал для улучшения реальных приложений искусственного интеллекта, делая высокопроизводительные модели более доступными и практичными. Вклад подтверждается серьезными экспериментами, демонстрирующими адаптивность и надежность MoNE на различных наборах данных и вычислительных бюджетах.

























