Allen Institute for AI (AI2) выпустил новый набор ресурсов OLMo 1B и 7B
Институт Allen для искусственного интеллекта AI2 сделал значительный шаг в развитии открытых языковых моделей с запуском OLMo (Open Language Model). Этот фреймворк предоставляет исследователям и академикам полный доступ к данным, коду обучения, моделям и инструментам оценки, способствуя совместным исследованиям в области искусственного интеллекта. Первоначальный релиз включает несколько вариантов моделей с 7 миллиардами параметров и модель с 1 миллиардом параметров, обученных на не менее чем 2 триллионах токенов.
Практические решения и ценность
Фреймворк OLMo разработан для того, чтобы дать сообществу искусственного интеллекта возможность исследовать более широкий спектр научных вопросов. Он позволяет изучать влияние конкретных подмножеств данных на производительность исследований и исследовать новые методы предварительного обучения. Этот открытый подход обеспечивает более глубокое понимание языковых моделей и их потенциальных нестабильностей, способствуя коллективному развитию науки об искусственном интеллекте.
Каждая модель OLMo поставляется с набором ресурсов, включая полные данные обучения, веса моделей, код обучения, журналы и метрики. Фреймворк также предоставляет более 500 контрольных точек для каждой базовой модели, адаптированные версии модели 7B (OLMo-7B-Instruct и OLMo-7B-SFT), код оценки и возможности тонкой настройки. Все компоненты выпущены под лицензией Apache 2.0, обеспечивая широкий доступ для исследовательского сообщества.
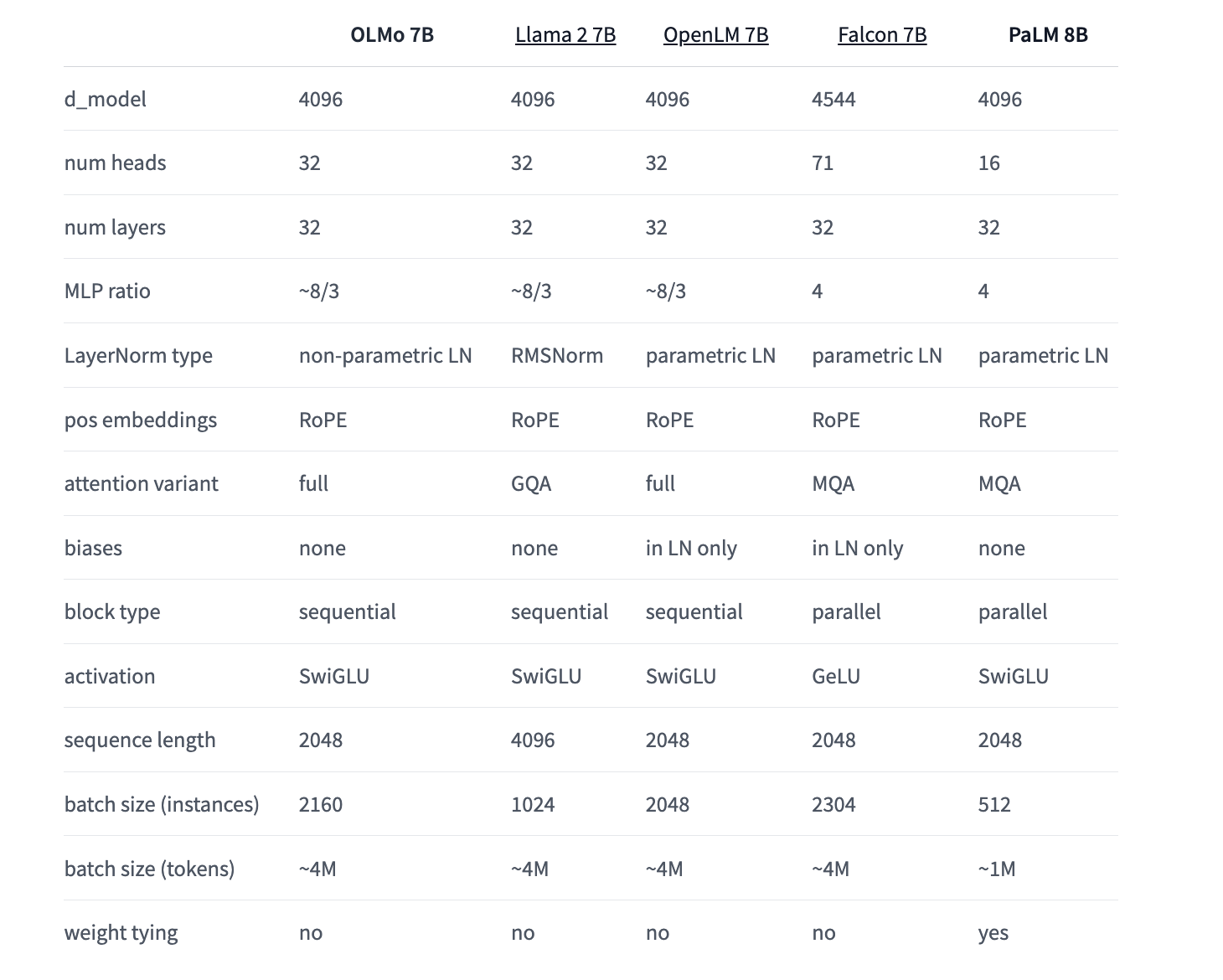
AI2 провела сравнительный анализ OLMo с другими открытыми и частично открытыми моделями, включая Pythia Suite от EleutherAI, модели MPT от MosaicML, модели Falcon от TII и серию моделей Llama от Meta. Результаты оценки показывают, что OLMo 7B конкурентоспособен с популярными моделями, демонстрируя сопоставимую производительность на многих задачах генерации и понимания текста, в то время как немного уступает в некоторых задачах вопросно-ответной системы.
AI2 разработал структурированный процесс выпуска OLMo и связанных инструментов. Регулярные обновления и новые ресурсы коммуницируются через шаблонные заметки о выпуске, которые распространяются в социальных сетях, на сайте AI2 и через рассылку. Такой подход обеспечивает информированность пользователей о последних разработках в экосистеме OLMo, включая Dolma и другие связанные инструменты.
Релиз OLMo июля 2024 года принес значительные улучшения как для модели 1B, так и для модели 7B. OLMo 1B июля 2024 года показал увеличение показателя HellaSwag на 4,4 пункта, наряду с другими улучшениями оценки, благодаря улучшенной версии набора данных Dolma и ступенчатому обучению. Аналогично, OLMo 7B июля 2024 года использовал самый новый набор данных Dolma и применил двухступенчатую программу обучения, последовательно добавляя 2-3 пункта улучшений производительности.
Ранние релизы, такие как OLMo 7B апреля 2024 года (ранее OLMo 7B 1.7), включали расширение длины контекста с 2048 до 4096 токенов и обучение на наборе данных Dolma 1.7. Эта версия превзошла модель Llama 2-7B по MMLU и приблизилась к производительности Llama 2-13B, превзойдя ее на GSM8K. Эти постепенные улучшения демонстрируют приверженность AI2 к постоянному улучшению фреймворка OLMo и моделей.
Релиз OLMo ставит только начало амбициозным планам AI2 по разработке открытых языковых моделей. В настоящее время ведется работа над различными размерами моделей, модальностями, наборами данных, мерами безопасности и оценками для семейства OLMo. AI2 стремится совместно построить лучшую в мире открытую языковую модель, приглашая сообщество искусственного интеллекта принять участие в этой инновационной инициативе.
Проверьте детали, OLMo 1B июля 2024, OLMo 7B июля 2024, OLMo 7B июля 2024 SFT, OLMo 7B июля 2024 Instruct. Вся заслуга за это исследование принадлежит исследователям этого проекта.
Не забудьте следить за нами в Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit по машинному обучению.
Находите предстоящие вебинары по искусственному интеллекту здесь.
Arcee AI выпустил DistillKit: открытый и простой в использовании инструмент для трансформации моделирования для создания эффективных малых языковых моделей
Институт Allen для искусственного интеллекта AI2 сделал значительный шаг в развитии открытых языковых моделей с запуском OLMo (Open Language Model). Этот фреймворк предоставляет исследователям и академикам полный доступ к данным, коду обучения, моделям и инструментам оценки, способствуя совместным исследованиям в области искусственного интеллекта. Первоначальный релиз включает несколько вариантов моделей с 7 миллиардами параметров и модель с 1 миллиардом параметров, обученных на не менее чем 2 триллионах токенов.

























