«`html
Преимущества самообучающихся оценщиков в области искусственного интеллекта
Развитие в области обработки естественного языка (NLP) привело к созданию больших языковых моделей (LLM), способных выполнять сложные задачи, связанные с языком, с высокой точностью. Эти достижения открыли новые возможности в технологиях и коммуникациях, позволяя более естественное и эффективное взаимодействие человека с компьютером.
Проблема и решение
Одной из основных проблем в NLP является зависимость от человеческих аннотаций для оценки моделей. Человеческие данные необходимы для обучения и проверки моделей, но их сбор является дорогостоящим и затратным по времени. Кроме того, по мере улучшения моделей ранее собранные аннотации могут потребовать обновления, что уменьшает их полезность для оценки новых моделей. Это создает постоянную потребность в новых данных, что затрудняет масштабирование и поддержание эффективной оценки моделей. Решение этой проблемы имеет ключевое значение для продвижения технологий NLP и их применений.
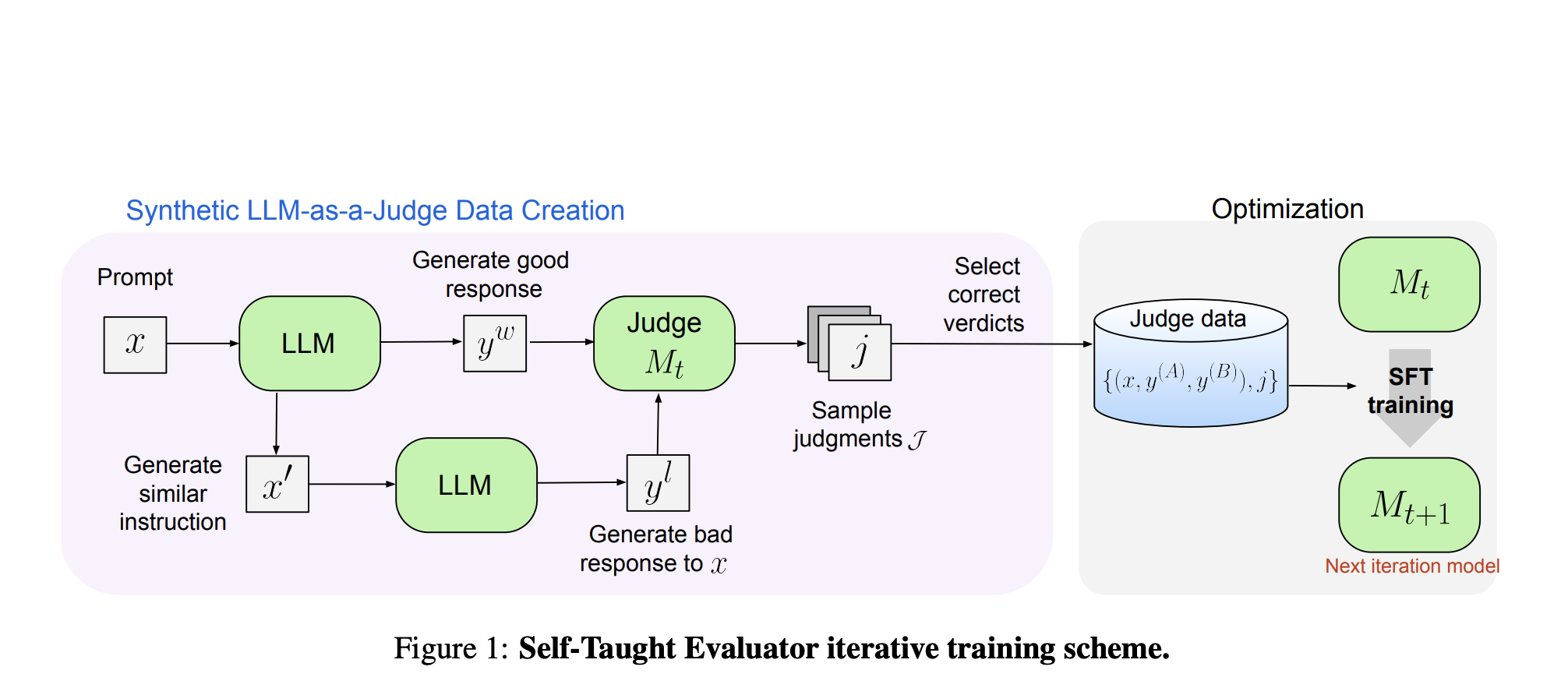
Новый подход
Исследователи из Meta FAIR предложили новый подход под названием «Самообучающийся оценщик». Этот метод устраняет необходимость в человеческих аннотациях, используя синтетически сгенерированные данные для обучения. Процесс начинается с базовой модели, которая создает контрастные синтетические пары предпочтений. Модель затем оценивает эти пары и итеративно улучшает свои способности, используя свои суждения для повышения производительности в последующих итерациях. Этот подход использует способность модели генерировать и оценивать данные, существенно уменьшая зависимость от человеческих аннотаций.
Результаты
Производительность самообучающегося оценщика была протестирована с использованием модели Llama-3-70B-Instruct. Метод улучшил точность модели на бенчмарке RewardBench с 75,4 до 88,7, сравнимую или превосходящую производительность моделей, обученных с использованием человеческих аннотаций. Это значительное улучшение демонстрирует эффективность синтетических данных в улучшении оценки модели. Кроме того, исследователи провели несколько итераций, дополнительно улучшая способности модели. Конечная модель достигла точности 88,3 с одним выводом и 88,7 с большинством голосов, показывая ее надежность и устойчивость.
Заключение
Самообучающийся оценщик предлагает масштабируемое и эффективное решение для оценки моделей NLP. Используя синтетические данные и итеративное самоусовершенствование, он решает проблемы зависимости от человеческих аннотаций и держит шаг с быстрыми достижениями в развитии языковых моделей. Этот подход повышает производительность модели и уменьшает зависимость от человеческих данных, открывая путь к более автономным и эффективным системам NLP. Работа исследовательской группы в Meta FAIR является значительным шагом в поиске более продвинутых и автономных методов оценки в области NLP.
«`

























