«`html
Оценка знаний в LLM с помощью KGLens
Большие языковые модели (LLM) привлекли значительное внимание своей универсальностью, но их достоверность остается критической проблемой. Исследования показали, что LLM могут производить недостоверную, выдуманную или устаревшую информацию, подрывая надежность. Текущие методы оценки, такие как факт-чекинг и факт-QA, сталкиваются с несколькими проблемами. Факт-чекингу трудно оценить достоверность созданного контента, а факт-QA сталкивается с трудностями в масштабировании данных из-за дорогостоящих процессов аннотации. Оба подхода также сталкиваются с риском загрязнения данных из предварительных корпусов веб-краулеров. Кроме того, LLM часто неоднозначно реагируют на один и тот же факт, представленный в различных формах, что требует адаптации существующих наборов данных для оценки.
Преимущества использования графов знаний
Существующие попытки оценить знания LLM в основном используют конкретные наборы данных, но сталкиваются с проблемами, такими как утечка данных, статический контент и ограниченные метрики. Графы знаний (KG) предлагают преимущества в настройке, развивающихся знаниях и уменьшении утечки тестовых наборов. Методы, такие как LAMA и LPAQA, используют графы знаний для оценки, но сталкиваются с неестественными форматами вопросов и непрактичностью для больших графов знаний. KaRR преодолевает некоторые проблемы, но остается неэффективным для больших графов и лишен обобщаемости. Текущие подходы сосредоточены на точности, не уделяя внимания надежности, не решая проблему неоднозначных ответов LLM на один и тот же факт. Также не существует работ, визуализирующих знания LLM с использованием графов знаний, что представляет возможность для улучшения.
Инновационный метод оценки знаний LLM
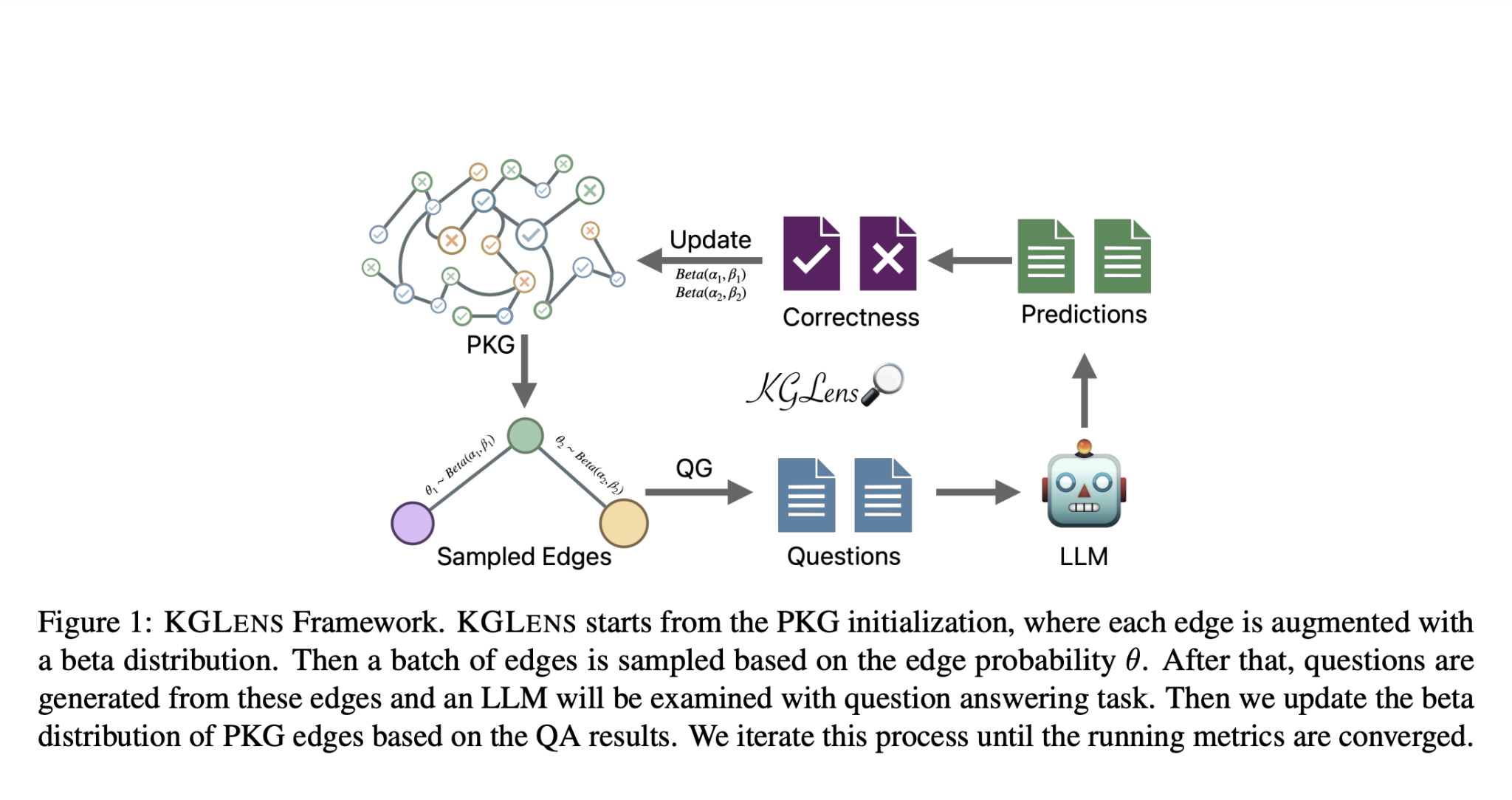
Исследователи из Apple представили KGLENS, инновационную систему оценки знаний, разработанную для измерения соответствия знаний между графами знаний и LLM и выявления слепых пятен в знаниях LLM. Система использует метод, вдохновленный выборочным распределением Томпсона, с параметризованным графом знаний (PKG) для эффективной оценки LLM. KGLENS представляет собой генератор вопросов, основанный на графе, который преобразует графы знаний в естественный язык с использованием GPT-4, создавая два типа вопросов (факт-чекинг и факт-QA) для уменьшения неоднозначности ответов. Человеческая оценка показывает, что 97,7% сгенерированных вопросов осмысленны для аннотаторов.
KGLENS использует уникальный подход для эффективной оценки знаний LLM с использованием PKG и метода, вдохновленного выборочным распределением Томпсона. Система инициализирует PKG, где каждое ребро дополняется бета-распределением, указывающим на потенциальные недостатки LLM на этом ребре. Затем происходит выборка ребер на основе их вероятности, генерация вопросов из этих ребер и проверка LLM через задачу вопросно-ответной системы. PKG обновляется на основе результатов, и этот процесс повторяется до сходимости. Также система представляет генератор вопросов, основанный на графе, который преобразует ребра графов знаний в вопросы естественного языка с использованием GPT-4. Создаются два типа вопросов: вопросы типа «да/нет» для оценки и вопросы типа «кто/что/где/когда/почему» для генерации, с типом вопроса, контролируемым структурой графа. Алиасы сущностей включены для уменьшения неоднозначности.
Для проверки ответов KGLENS указывает LLM на генерацию конкретных форматов ответов и использует GPT-4 для проверки правильности ответов на вопросы типа «кто/что/где/когда/почему». Эффективность системы оценивается с помощью различных методов выборки, демонстрируя ее эффективность в выявлении слепых пятен в знаниях LLM по различным темам и отношениям.
Оценка KGLENS различных LLM показывает, что семейство GPT-4 постоянно превосходит другие модели. GPT-4, GPT-4o и GPT-4-turbo показывают сопоставимую производительность, при этом GPT-4o более осторожен в отношении личной информации. Существует значительное различие между GPT-3.5-turbo и GPT-4, причем GPT-3.5-turbo иногда производит худшие результаты по сравнению с устаревшими LLM из-за своего консервативного подхода. Устаревшие модели, такие как Babbage-002 и Davinci-002, показывают лишь незначительное улучшение по сравнению с случайным угадыванием, что подчеркивает прогресс в недавних LLM. Оценка предоставляет понимание различных типов ошибок и поведения моделей, демонстрируя разнообразные возможности LLM в обработке различных областей знаний и уровней сложности.
KGLENS представляет эффективный метод оценки фактических знаний в LLM с использованием метода, вдохновленного выборочным распределением Томпсона, с параметризованными графами знаний. Система превосходит существующие методы в выявлении слепых пятен в знаниях и демонстрирует адаптивность в различных областях. Человеческая оценка подтверждает ее эффективность, достигая 95,7% точности. KGLENS и его оценка графов знаний будут доступны исследовательскому сообществу, способствуя сотрудничеству. Для бизнеса это инструмент облегчает разработку более надежных систем ИИ, улучшая пользовательские впечатления и знания модели. KGLENS представляет собой значительный прогресс в создании более точных и надежных приложений ИИ.
«`

























