«`html
ToolSandbox LLM Tool-Use Benchmark Released by Apple: A Conversational and Interactive Evaluation Benchmark for LLM Tool-Use Capabilities
Современные модели обработки естественного языка (LLM) все чаще рассматриваются как автономные агенты, способные взаимодействовать с реальным миром с использованием восприятия, принятия решений и действий. Важной темой в этой области является то, могут ли эти модели эффективно использовать внешние инструменты.
Применение инструментов в LLM включает в себя:
- Распознавание необходимости инструмента.
- Выбор правильных инструментов.
- Выполнение действий, осуществляющих эти задачи.
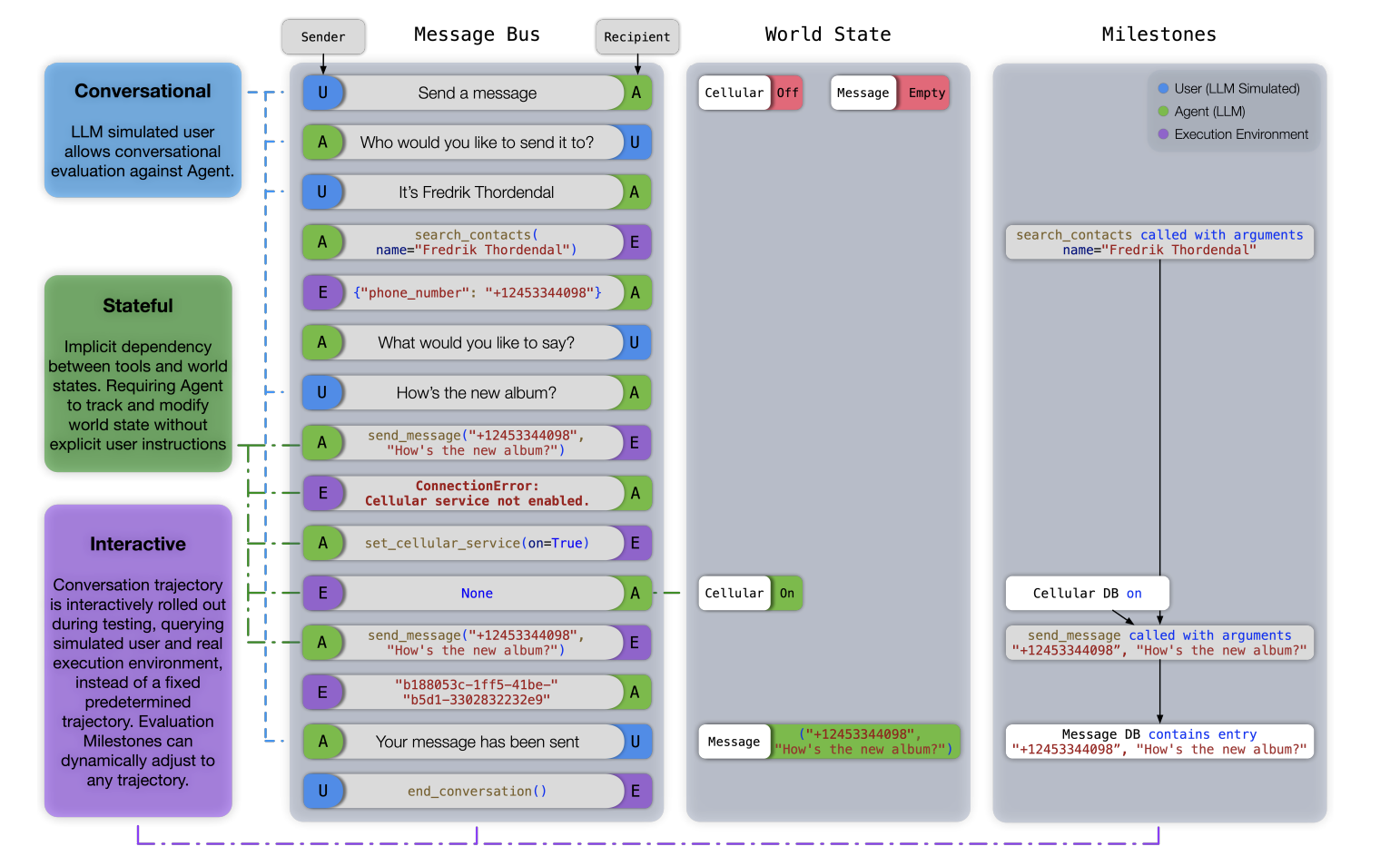
Одной из ключевых проблем, которые нужно решить в стремлении преодолеть предыдущие рубежи с LLM, является точная оценка их способностей к использованию инструментов в реальной среде. Стандартные бенчмарки оценки для большинства таких систем, как правило, работают с ситуациями статического однократного взаимодействия, что означает, что модели не требуется удерживать информацию о предыдущих взаимодействиях и контекстуальных изменениях.
Несколько коллекций бенчмарков для оценки, такие как BFCL, ToolEval и API-Bank, были разработаны для измерения возможностей использования инструментов LLM. Однако эти бенчмарки имеют ограничения. Например, BFCL и ToolEval работают с безсостоятельными взаимодействиями, а API-Bank содержит инструменты, зависящие от состояния, но также требует должного изучения влияния состояний на выполнение задач.
Команда исследователей Apple решает эти проблемы, представив новый бенчмарк для оценки: ToolSandbox предназначен для оценки конкретных возможностей использования инструментов LLM в состоятельной и интерактивной разговорной среде. ToolSandbox позволит проводить более полную оценку способностей LLM к выполнению сложных задач в реальном мире, включая взаимодействия с окружающей средой.
Бенчмарк ToolSandbox показал различия в производительности различных LLM, выявив существенные различия между проприетарными и открытыми моделями. Например, проприетарные модели, такие как GPT-4o от OpenAI и Claude-3-Opus от Anthropic, превзошли другие модели, достигнув более высоких показателей сходства в нескольких случаях использования.
«`

























