Инновационные решения в области искусственного интеллекта
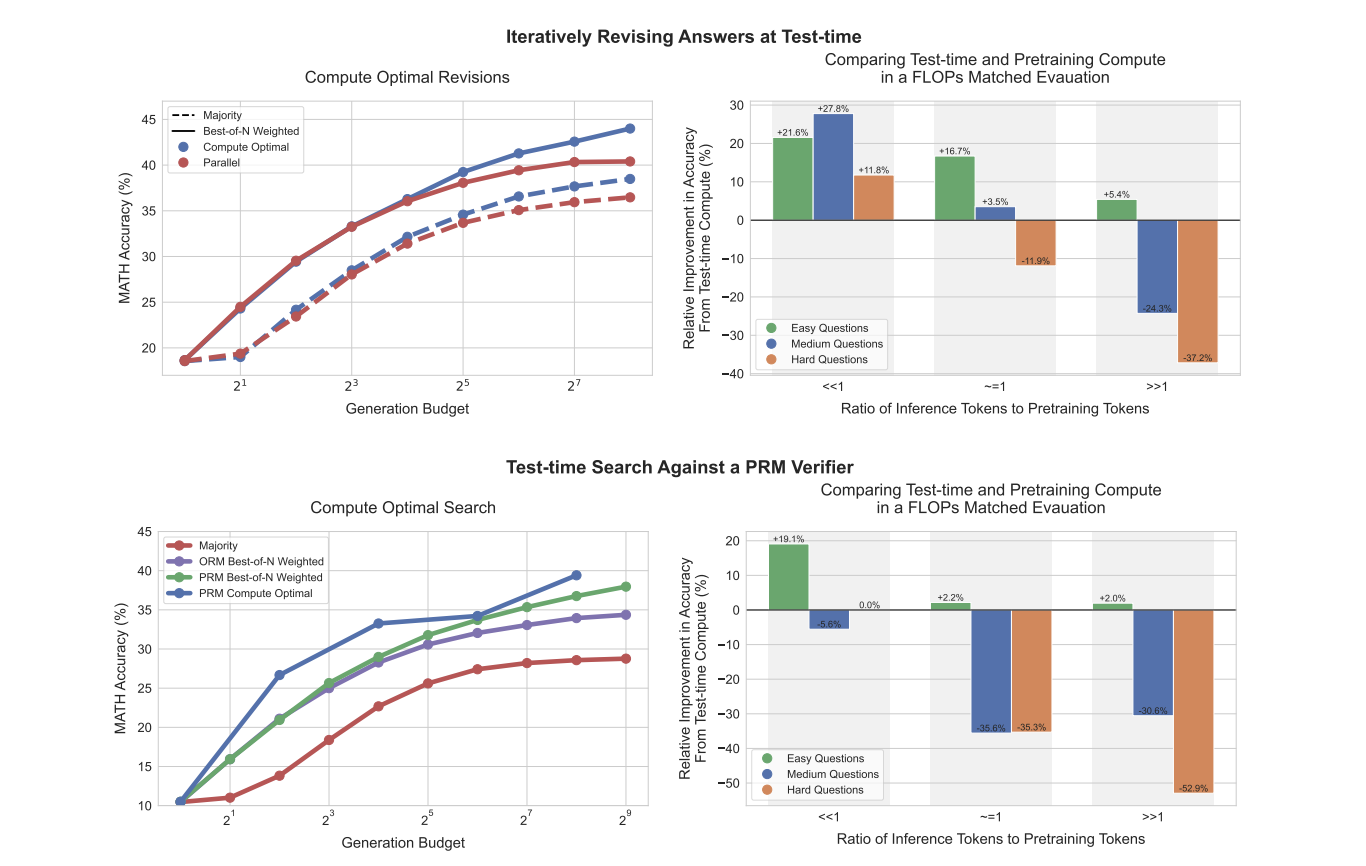
Большие языковые модели (LLM) сталкиваются с вызовами в эффективном использовании дополнительных вычислений во время тестирования для улучшения точности своих ответов, особенно в сложных задачах. Исследователи ищут способы, чтобы LLM могли дольше размышлять над трудными проблемами, подобно человеческому мышлению. Эта способность, возможно, может открыть новые возможности в задачах агентства и рассуждения, позволить более компактным моделям на устройствах заменить LLM на масштабах центров обработки данных и создать путь к общим алгоритмам самоусовершенствования с уменьшенным участием человека.
Практические решения и ценность
Исследователи значительно продвинулись в улучшении производительности языковых моделей в математических задачах рассуждения через различные методы. Это включает продолжение предварительного обучения на данных, сфокусированных на математике, улучшение распределения предложений LLM через целенаправленную оптимизацию и итерационную переработку ответов, а также обеспечение LLM дополнительными вычислениями во время тестирования с использованием настраиваемых проверяющих. Несколько методов были предложены для дополнения LLM тестовыми вычислениями, такие как иерархический поиск гипотез для индуктивного рассуждения, дополнение инструментов и изучение мыслей для более эффективного использования дополнительных тестовых вычислений.
Исследователи из UC Berkeley и Google DeepMind предлагают адаптивную «вычислительно-оптимальную» стратегию для масштабирования тестовых вычислений в LLM. Этот подход выбирает наиболее эффективный метод использования дополнительных вычислений на основе конкретного запроса и сложности вопроса. Путем использования меры сложности вопроса с точки зрения базовой LLM, исследователи могут предсказать эффективность тестовых вычислений и применить эту вычислительно-оптимальную стратегию на практике.
Использование дополнительных тестовых вычислений в LLM можно рассматривать через единую перспективу модификации предсказанного распределения модели адаптивно на тестирование. Это изменение может быть достигнуто двумя основными подходами: изменением распределения предложений и оптимизацией проверяющего. Для улучшения распределения предложений исследователи исследовали методы, такие как RL-вдохновленная настройка (например, STaR, ReSTEM) и техники самокритики. Для оптимизации проверяющего метода традиционный метод выбора лучшего из N может быть улучшен путем обучения проверяющего или модели вознаграждения процесса (PRM).
Адаптивное распределение ресурсов тестового времени приводит к значительному улучшению производительности по сравнению с равномерными или ад-хок стратегиями распределения вычислений. Эти выводы указывают на потенциальный сдвиг в направлении выделения меньшего количества FLOP для предварительного обучения и большего количества для вывода в будущем, подчеркивая изменяющийся ландшафт оптимизации и развертывания LLM.

























