Использование крупных языковых моделей в области обработки естественного языка
Крупные языковые модели (LLM) значительно изменили область обработки естественного языка, позволяя машинам понимать и генерировать человеческий язык намного эффективнее, чем когда-либо прежде. Обычно эти модели предварительно обучаются на огромных параллельных корпусах, а затем донастраиваются для выполнения различных задач или удовлетворения человеческих предпочтений.
Оптимизация процесса обучения
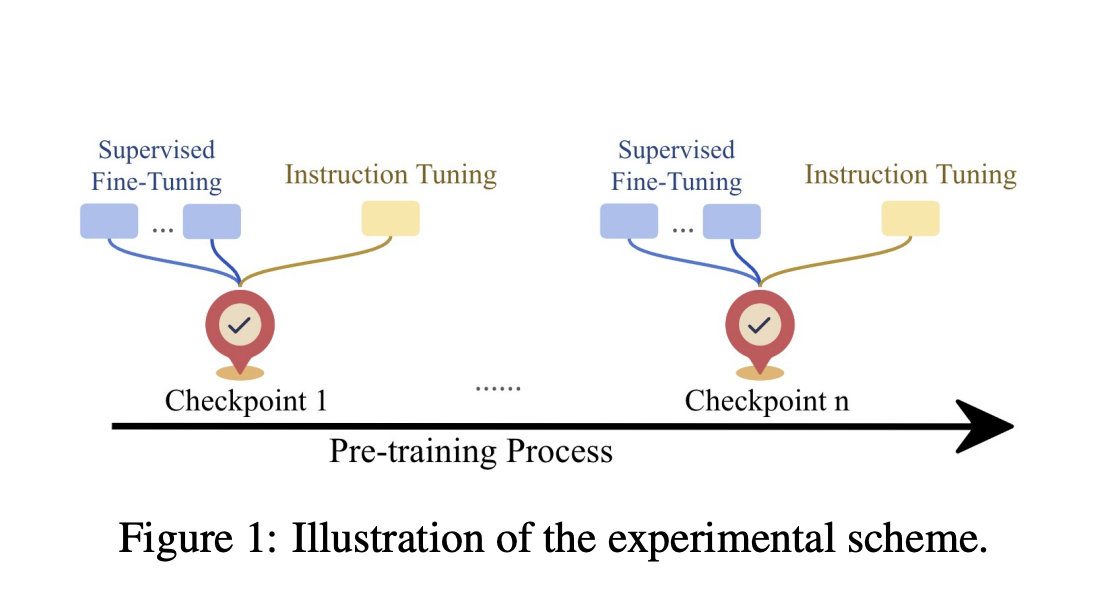
Одна из сложных задач в обучении LLM заключается в нахождении баланса между предварительным обучением и донастройкой. Предварительное обучение играет ключевую роль в придании моделям широкого понимания языка, но часто возникает дискуссия о том, насколько оптимальной является точка предварительного обучения перед донастройкой.
Новые методологии и подходы
Исследователи начали изучать более интегрированный подход, в котором донастройка вводится на разных этапах предварительного обучения, чтобы достичь лучшей производительности. Недавно была предложена новая методология, исследующая компромисс между предварительным обучением и донастройкой, что привело к значительным улучшениям в производительности моделей.
Практические результаты и выводы
Эти исследования показали, что непрерывное предварительное обучение приводит к потенциальным скрытым возможностям модели, которые проявляются только после донастройки. Особенно важно отметить, что донастройка значительно улучшает производительность моделей в случаях, когда базовая модель показывает недостаточные результаты.
В целом, эта работа исследователей из Университета Джонса Хопкинса предоставляет важное понимание динамических взаимосвязей между предварительным обучением и донастройкой в области LLM. Это открывает новые перспективы для области обработки естественного языка и обещает привести к более эффективным и гибким языковым моделям.

























