«`html
Улучшение объяснимости обучения с подкреплением с помощью временного разложения вознаграждения
Оценка будущего вознаграждения является ключевой в обучении с подкреплением, поскольку она предсказывает накопленные вознаграждения, которые агент может получить, обычно через функции Q-значений или значений состояния. Однако эти скалярные выходы не содержат подробной информации о том, когда или какие конкретные вознаграждения агент ожидает. Это ограничение имеет большое значение в приложениях, где важны человеческое сотрудничество и объяснимость. Например, в ситуации, когда беспилотный летательный аппарат должен выбрать между двумя путями с разными вознаграждениями, только значения Q не раскрывают характер вознаграждений, что важно для понимания процесса принятия решений агента.
Практические решения и ценность
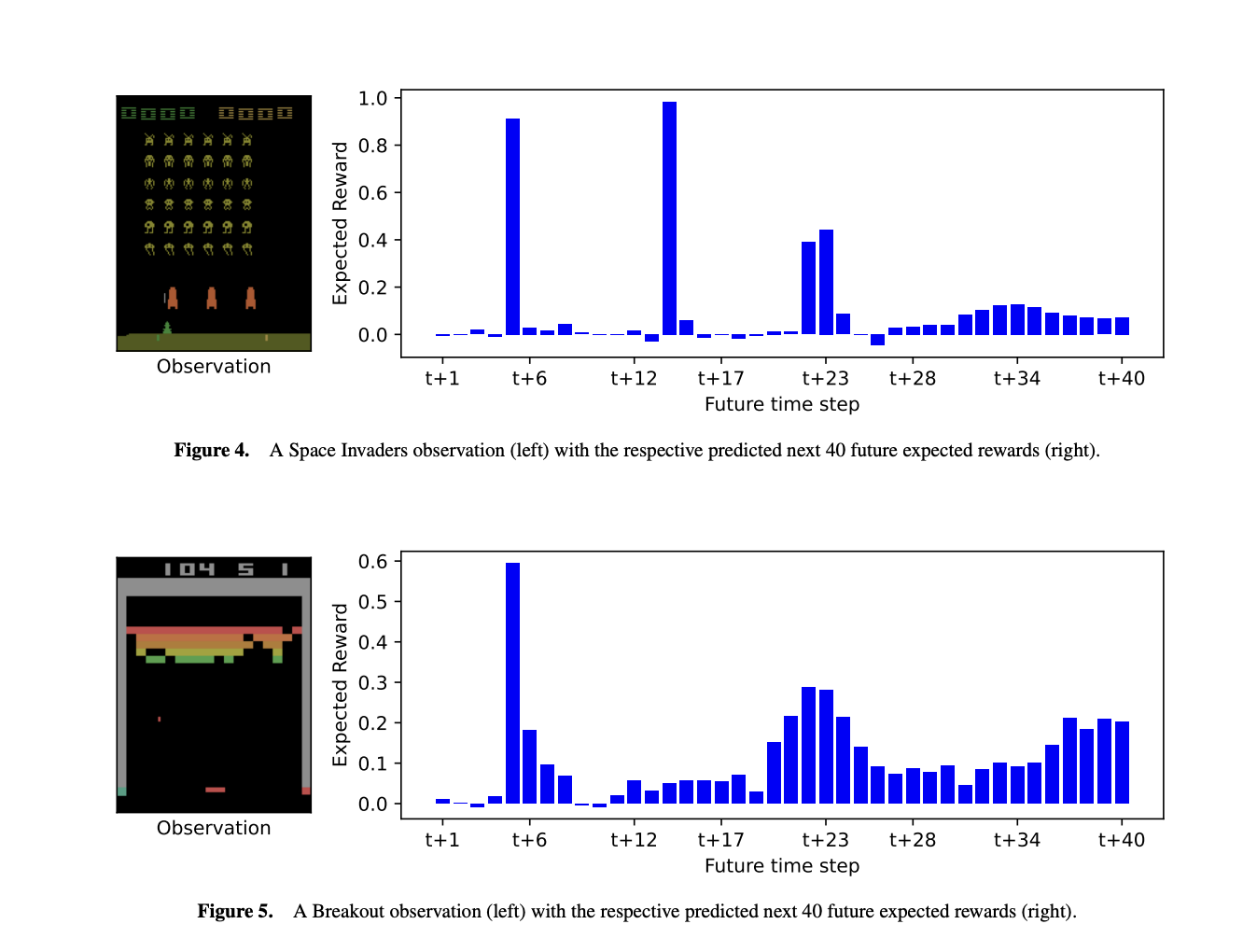
Исследователи из Университета Саутгемптона и Королевского колледжа Лондона представили временное разложение вознаграждения (TRD) для улучшения объяснимости в обучении с подкреплением. TRD модифицирует оценщик будущего вознаграждения агента для предсказания следующих N ожидаемых вознаграждений, раскрывая, когда и какие вознаграждения ожидаются. Этот подход позволяет лучше интерпретировать решения агента, объясняя время и значение ожидаемых вознаграждений и влияние различных действий. С минимальным влиянием на производительность TRD может быть интегрирован в существующие модели обучения с подкреплением, такие как агенты DQN, предлагая ценные исследования поведения агента и процессов принятия решений в сложных средах.
Исследование фокусируется на существующих методах объяснения принятия решений агентами обучения с подкреплением на основе вознаграждений. Предыдущие работы исследовали разложение значений Q на составляющие вознаграждения или будущие состояния. Некоторые методы сравнивают источники вознаграждений, такие как монеты и сундуки с сокровищами, в то время как другие разлагают значения Q по важности состояния или вероятностям перехода. Однако эти подходы должны учитывать время вознаграждений и могут не масштабироваться до сложных сред. Альтернативы, такие как формирование вознаграждений или карты выделения, предлагают объяснения, но требуют модификаций среды или фокусируются на визуальных областях, а не на конкретных вознаграждениях. TRD представляет подход, разлагая значения Q во времени, что позволяет использовать новые методы объяснения.
Исследование вводит основные концепции для понимания фреймворка TRD. Оно начинается с процессов принятия решений Маркова (MDP), основы обучения с подкреплением, моделирующих среды с состояниями, действиями, вознаграждениями и переходами. Затем обсуждается глубокое Q-обучение, подчеркивая его использование нейронных сетей для приближения значений Q в сложных средах. QDagger представлен для сокращения времени обучения путем извлечения знаний от учителя-агента. Наконец, объясняется GradCAM как инструмент для визуализации, какие функции влияют на решения нейронной сети, обеспечивая интерпретируемость выводов модели. Эти концепции являются основополагающими для понимания подхода TRD.
Исследование представляет три метода объяснения будущих вознаграждений агента и процессов принятия решений в средах обучения с подкреплением. Во-первых, оно описывает, как TRD предсказывает, когда и какие вознаграждения агент ожидает, помогая понять поведение агента в сложных средах, таких как игры Atari. Во-вторых, оно использует GradCAM для визуализации, какие функции наблюдения влияют на предсказания ближайших и отдаленных вознаграждений. Наконец, оно использует контрастные объяснения для сравнения влияния различных действий на будущие вознаграждения, подчеркивая, как немедленные и отсроченные вознаграждения влияют на принятие решений. Эти методы предлагают новые исследования поведения агента и процессов принятия решений.
В заключение, TRD улучшает понимание агентов обучения с подкреплением, предоставляя подробные исследования будущих вознаграждений. TRD может быть интегрирован в предварительно обученные агенты Atari с минимальной потерей производительности. Он предлагает три ключевых инструмента объяснения: предсказание будущих вознаграждений и уверенности агента в них, определение того, как важность функций меняется с течением времени вознаграждения, и сравнение влияния различных действий на будущие вознаграждения. TRD раскрывает более детальные сведения о поведении агента, такие как время вознаграждения и уверенность, и может быть расширен с помощью дополнительных подходов разложения или распределений вероятностей для будущих исследований.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта.
Не забудьте подписаться на нашу группу в Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу на Reddit.
Найдите предстоящие вебинары по ИИ здесь.
Arcee AI представляет Arcee Swarm: Революционное смешение агентов MoA Architecture, вдохновленное кооперативным интеллектом, обнаруженным в самой природе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Enhancing Reinforcement Learning Explainability with Temporal Reward Decomposition.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на нашем канале в Telegram.
Попробуйте ИИ ассистент в продажах. Этот ИИ ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
«`

























