«`html
Решения искусственного интеллекта для анализа табличных данных
Табличные данные, которые преобладают во многих областях, таких как здравоохранение, финансы и социальные науки, содержат строки и столбцы с структурированными признаками, что значительно облегчает управление или анализ данных. Однако разнообразие табличных данных, включая числовые, условные и текстовые, представляет огромные вызовы для достижения надежной и точной прогностической производительности. Еще одной областью для улучшения в моделировании и анализе этого типа данных является сложность взаимосвязей внутри данных, особенно зависимости между строками и столбцами.
Основные вызовы и практические решения
Основной вызов в анализе табличных данных заключается в том, что очень сложно обрабатывать их гетерогенную структуру. Традиционные модели машинного обучения далеко отстают, особенно для больших и сложных наборов данных. Эти модели требуют дополнительного руководства для хорошей обобщенности в присутствии разнообразия типов данных и взаимосвязей табличных данных. Этот вызов становится еще более сложным, учитывая необходимость высокой прогностической точности и надежности, особенно в критических приложениях, таких как здравоохранение.
Для преодоления этих вызовов были применены различные методы моделирования табличных данных. Ранние техники в основном опирались на традиционное машинное обучение, большинство из которых требовали много инженерии признаков для моделирования тонкостей данных. Известной слабостью этих методов является их неспособность масштабироваться по размеру и сложности входного набора данных. Более недавно методы из обработки естественного языка были адаптированы для табличных данных; более конкретно, архитектуры на основе трансформаторов все более реализуются. Эти методы начались с обучения трансформаторов с нуля по табличным данным, но это имело недостаток в необходимости большого количества обучающих данных с существенными проблемами масштабируемости. На этом фоне исследователи начали использовать промежуточные языковые модели, такие как BERT, которые требовали меньше данных и обеспечивали лучшую прогностическую производительность.
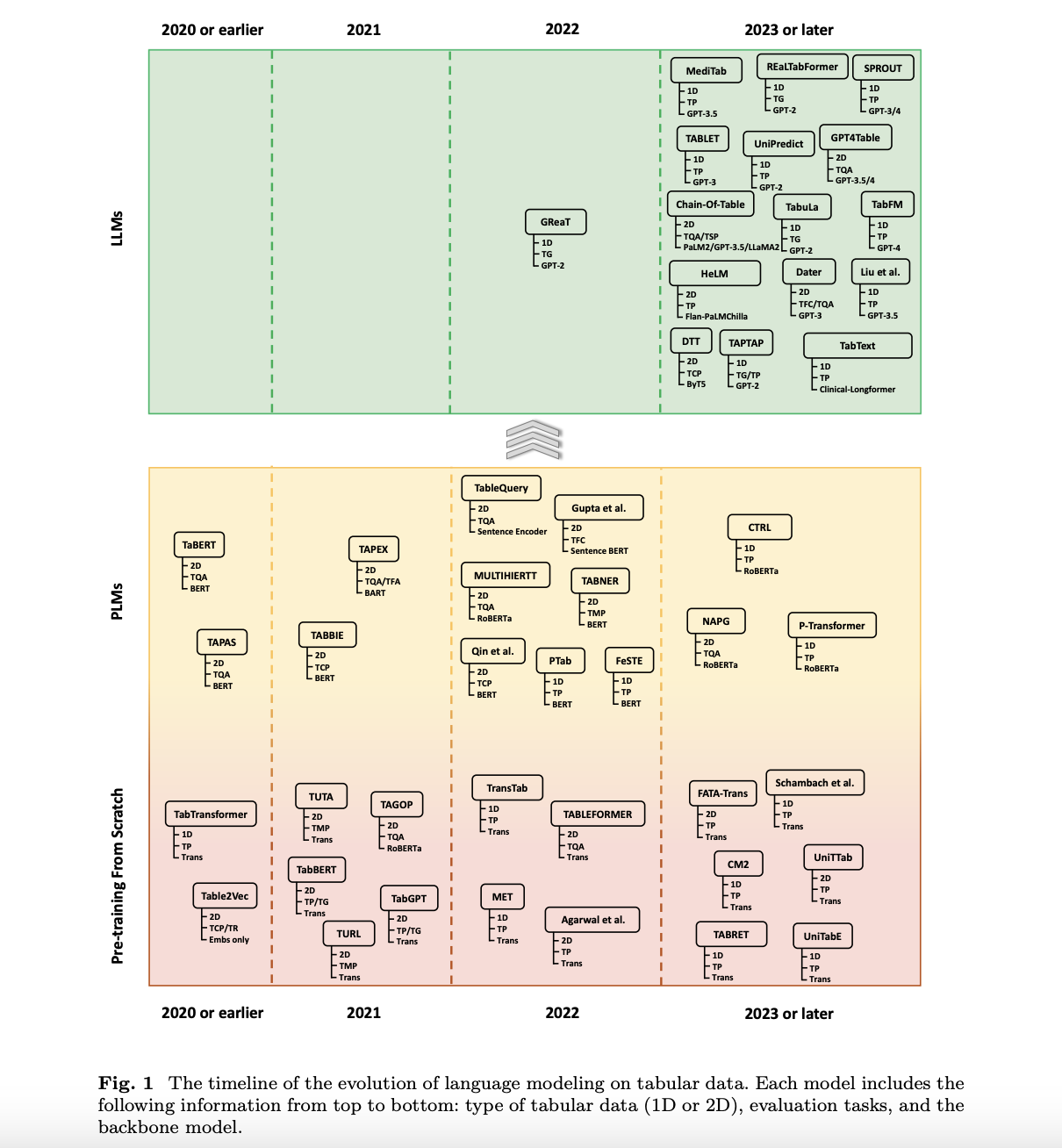
Исследователи из Национального университета Сингапура предоставили всесторонний обзор различных техник языкового моделирования, разработанных для табличных данных. Обзор систематизирует классификацию литературы и дополнительно выявляет сдвиг тенденций от традиционных моделей машинного обучения к продвинутым методам, использующим передовые LLMs, такие как GPT и LLaMA. Это исследование подчеркивает эволюцию этих моделей, показывая, насколько LLMs были радикальны в этой области, уводя ее дальше в более сложные приложения в моделировании табличных данных. Эта работа важна для заполнения пробела в соответствующей литературе, предоставляя детальную таксономию структур табличных данных, ключевые наборы данных и различные методы моделирования.
Методология, предложенная исследовательской группой, категоризирует табличные данные на два основных типа: 1D и 2D. С другой стороны, 1D табличные данные обычно содержат только одну таблицу, с основной работой на уровне строк, что, конечно, является более простым, но очень важным для задач, таких как классификация и регрессия. В отличие от этого, 2D табличные данные состоят из нескольких связанных таблиц, требуя более сложных техник моделирования для задач, таких как извлечение таблиц и вопросно-ответное моделирование таблиц. Исследователи углубляются в различные стратегии преобразования табличных данных в формы, которые может потреблять их языковая модель. Эти стратегии включают выравнивание последовательностей, обработку строк и интеграцию этой информации в запросы. Через эти методы языковые модели используют более глубокое понимание и способности обработки табличных данных для обеспечения гарантированных прогностических результатов.
Исследование показывает, насколько сильны способности больших языковых моделей в большинстве задач с табличными данными. Эти модели продемонстрировали значительное улучшение в понимании и обработке сложных структур данных в функциях, таких как вопросно-ответное моделирование таблиц и семантический анализ таблиц. Авторы показывают, как LLMs обеспечивают стандартный рост во всех задачах на более высоких уровнях точности и эффективности, используя предварительные знания и продвинутые механизмы внимания, устанавливающие новые стандарты моделирования табличных данных во многих приложениях.
В заключение, исследование подчеркивает потенциал, который имеют техники обработки естественного языка для эффективного изменения самой природы анализа табличных данных в присутствии больших языковых моделей. Систематизируя обзор и категоризацию существующих методов, исследователи предложили очень ясную дорожную карту для будущих разработок в этой области. Предложенные методологии опровергают внутренние вызовы табличных данных и открывают новые продвинутые приложения с гарантиями актуальности и эффективности, включая случаи, когда сложность данных возрастает.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте This AI Paper by National University of Singapore Introduces A Comprehensive Survey of Language Models for Tabular Data Analysis.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/ Этот ИИ ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
«`

























