Понимание устной речи для больших языковых моделей (LLM) — ключевой аспект создания более естественного и интуитивного взаимодействия с машинами.
Традиционные модели отлично справляются с текстовыми задачами, но испытывают трудности с пониманием устной речи, что ограничивает их потенциал в приложениях реального мира, таких как голосовые ассистенты, обслуживание клиентов и инструменты доступности.
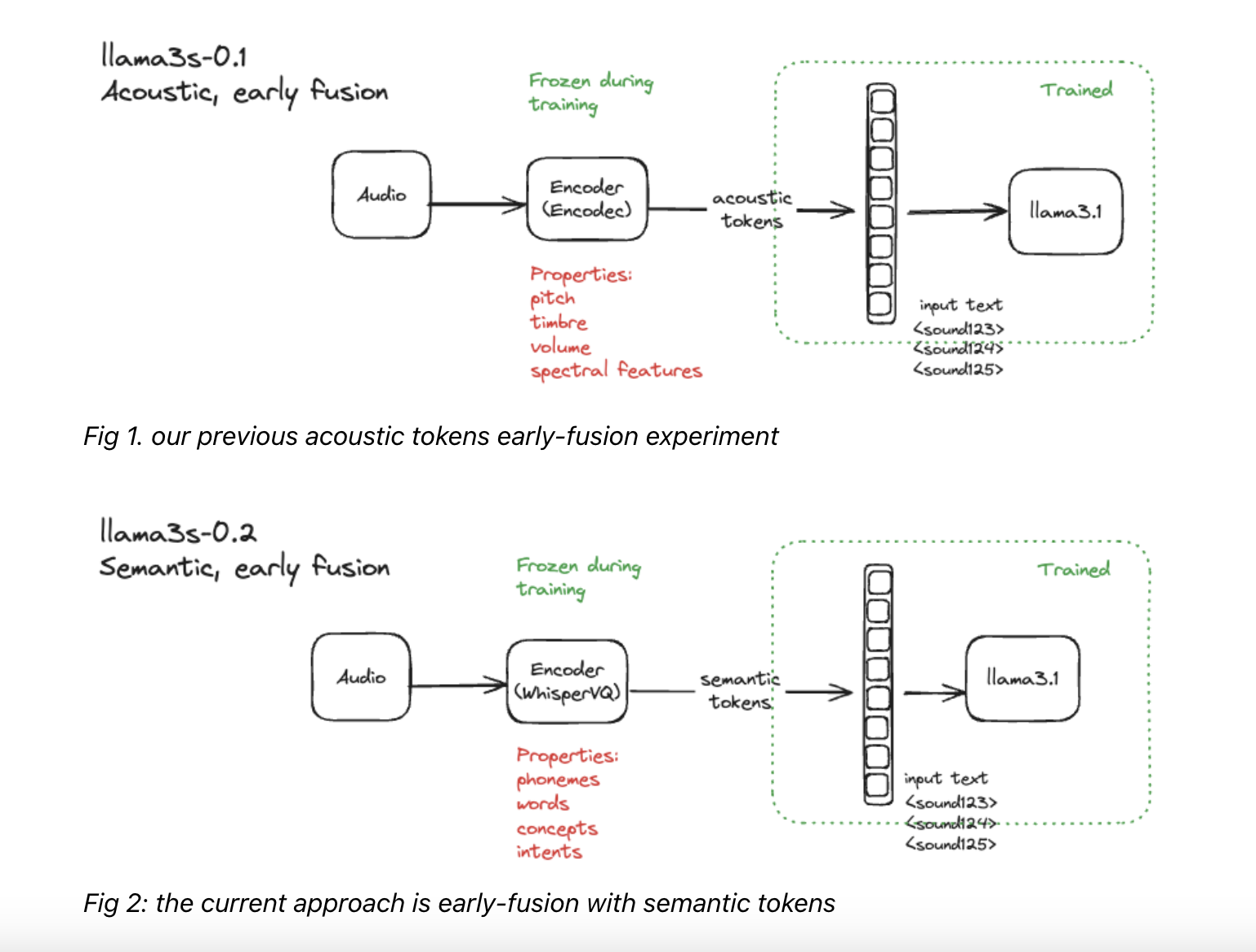
Решение от Homebrew Research: Llama3-s v0.2
Новая модель Llama3-s v0.2 разработана для улучшения понимания устной речи в обработке естественного языка. Она использует предварительно обученный аудио-кодер (например, WhisperVQ), чтобы преобразовать устную речь в числовые представления, которые модель может обрабатывать. Это мультимодальный подход позволяет модели эффективно учиться отношениям между устной речью и ее текстовым представлением, а также использовать семантические токены для улучшения понимания содержания речи.
Модель проходит двухэтапный процесс обучения на реальных и синтетических данных, что позволяет ей превзойти существующие модели по нескольким показателям.
Выводы и возможности
Llama3-s v0.2 представляет собой значительный шаг в развитии мультимодальных языковых моделей, способных понимать устную речь. Использование аудио и текстовых входов, а также продвинутая семантическая токенизация позволяют модели преодолеть ограничения традиционных языковых моделей в понимании речи, открывая новые возможности для реальных приложений и делая технологии более доступными и удобными для пользователей.

























