«`html
Retrieval Augmented Generation (RAG) — передовой метод в искусственном интеллекте
RAG представляет собой передовой метод в области искусственного интеллекта, особенно в обработке естественного языка (NLP) и информационном поиске (IR). Он разработан для улучшения возможностей больших языковых моделей (LLM) путем интеграции контекстно-релевантной, актуальной и предметно-специфичной информации в их ответы. Это позволяет LLM более точно и эффективно выполнять задачи, особенно там, где важна собственная или актуальная информация. RAG привлек внимание, так как он решает проблему более точных и осведомленных выводов в системах, управляемых искусственным интеллектом. Это требование становится все более важным с увеличением сложности задач и запросов пользователей.
Основные преимущества нового подхода:
- Интеграция контекстно-релевантной информации для более точных ответов
- Улучшение возможностей больших языковых моделей (LLM)
- Решение проблемы точности и контекстуальной релевантности в информационном поиске
Основные вызовы и решения:
- Синтез информации из больших и разнообразных наборов данных
- Проблемы семантического контекста при разбиении документов на части
- Применение новой методологии, включающей генерацию метаданных и синтетических вопросов и ответов (QA)
Практические преимущества:
- Улучшение точности, полноты и релевантности результатов информационного поиска
- Снижение затрат на обработку данных и повышение масштабируемости
- Применение в различных областях знаний и задачах, требующих точности и контекстуальной релевантности
Инновационный подход к Retrieval Augmented Generation
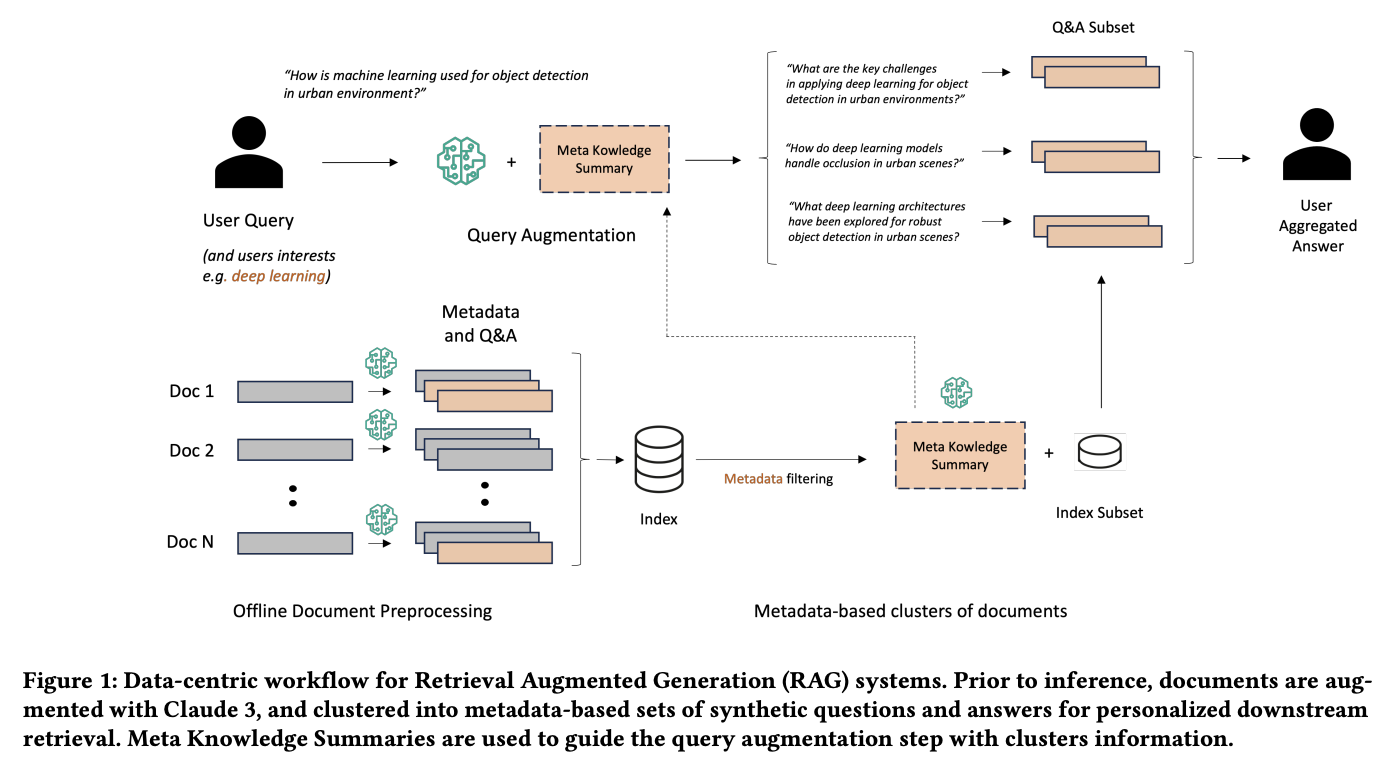
Команда исследователей из Amazon Web Services представила новую методологию, которая значительно улучшает традиционные системы RAG. Они предложили эффективный подход, который включает в себя генерацию метаданных и синтетических QA для каждого документа, а также внедрение концепции Meta Knowledge Summary (MK Summary). Этот подход отличается от простого поиска и чтения фрагментов документов, предлагая более комплексный метод подготовки, переписывания и извлечения информации для соответствия запросам пользователей.
Практические результаты исследования:
- Улучшение точности, полноты и релевантности результатов информационного поиска
- Метод позволяет расширить область поиска на 20%
- Повышение релевантности ответов до 90.22%
Заключение
Инновационный подход к Retrieval Augmented Generation решает ключевые проблемы традиционных систем RAG, обеспечивая более точные, релевантные и полные ответы. Это улучшает качество информационных систем, управляемых искусственным интеллектом, и предлагает масштабируемое решение, применимое в различных областях знаний. Подобные инновационные подходы будут критически важны для обеспечения точности и контекстуальной релевантности в информационном поиске с развитием искусственного интеллекта.
«`

























