«`html
Преимущества использования модели Arctic-SnowCoder-1.3B в сфере разработки программного обеспечения
Модели машинного обучения, особенно те, которые предназначены для генерации кода, сильно зависят от качественных данных во время предварительного обучения. Недавние исследования показали значительный прогресс в этой области с использованием больших языковых моделей, обученных на обширных наборах данных, содержащих код из различных источников. Однако для исследователей представляется вызовом обеспечение изобилия и высокого качества данных, поскольку это существенно влияет на способность модели решать сложные задачи. В прикладных приложениях, хорошо структурированные, аннотированные и чистые данные гарантируют, что модели могут генерировать точные, эффективные и надежные результаты для реальных задач программирования.
Проблемы и решения в развитии моделей генерации кода
Одной из значительных проблем разработки моделей генерации кода является недостаточно точное определение «высококачественных» данных. Большинство данных содержат шум, избыточность или ненужную информацию, что может снизить производительность модели. Однако использование сырых данных, даже после фильтрации, часто приводит к неэффективности. Для решения этой проблемы требуется фокусироваться не только на получении больших объемов данных, но и на курировании данных, соответствующих задачам приложений. Такой подход повышает предсказательные способности модели и ее полезность в целом.
Исторически предварительное обучение моделей кода включало извлечение данных из крупных репозиториев, таких как GitHub, и их обработку с помощью базовых методов фильтрации и удаления дубликатов. Однако эти методы не всегда обеспечивали оптимальную производительность на более сложных задачах программирования. Новые подходы начали использовать более сложные инструменты, такие как аннотаторы на основе BERT, для классификации качества кода и отбора данных, способствующих успеху модели.
Исследование Arctic-SnowCoder-1.3B и его результаты
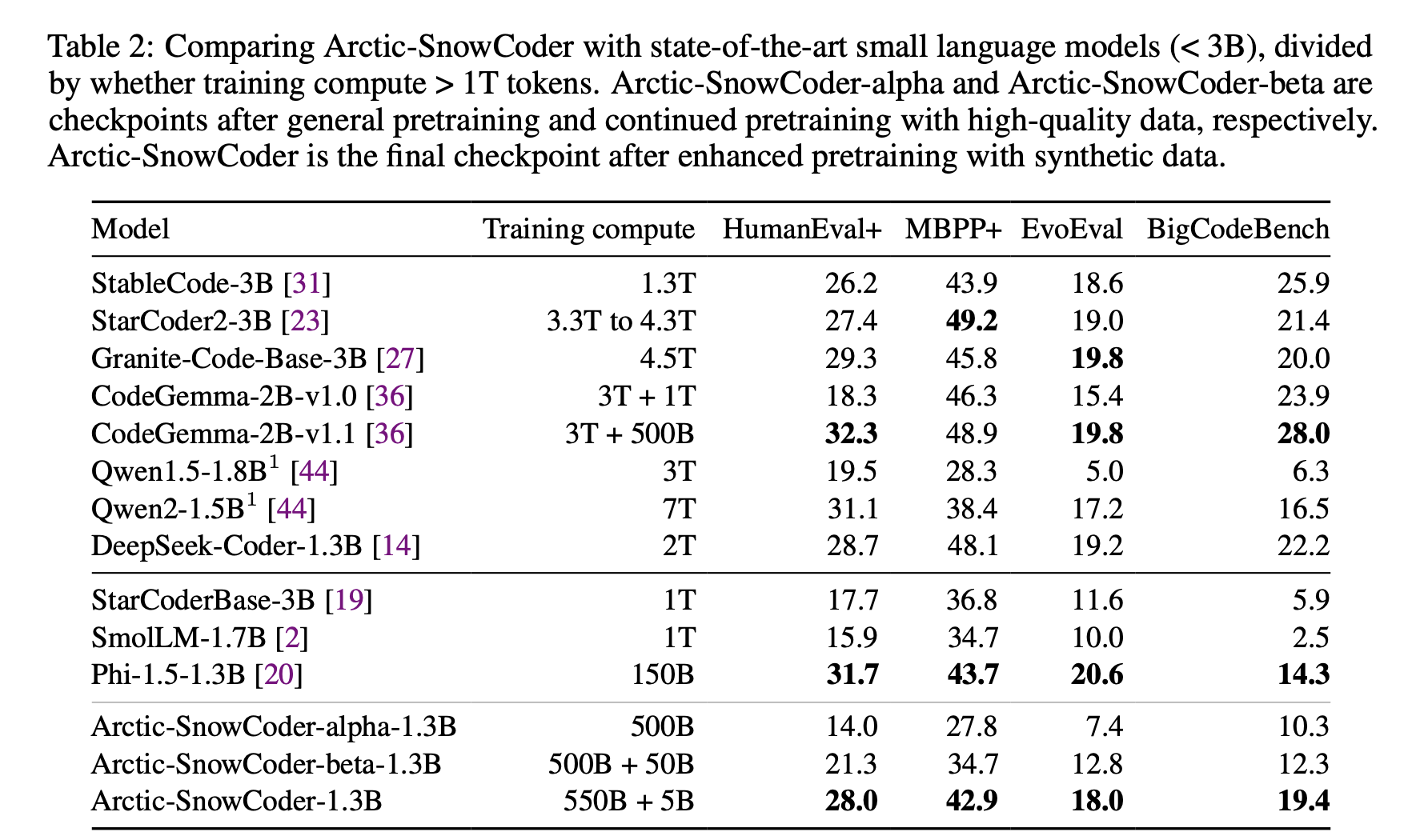
Исследовательская группа из Snowflake AI Research, University of Illinois at Urbana-Champaign и Seoul National University представила новый подход к предварительному обучению моделей кода, который последовательно улучшал качество данных на трех этапах. Этот метод включал общее предварительное обучение, продолжение обучения с использованием высококачественных данных и окончательное обучение с использованием синтетических данных. Результатом стало создание более маленькой и эффективной модели, которая превзошла конкурентов благодаря оптимизации данных на каждом этапе.
На первом этапе Arctic-SnowCoder был обучен на 500 миллиардах токенов кода из источников, таких как The Stack v1 и GitHub. Эти данные прошли базовую предварительную обработку, включая фильтрацию и удаление дубликатов, что привело к приблизительно 400 миллиардам уникальных токенов. На втором этапе исследователи выбрали 50 миллиардов токенов из начального набора данных, сосредотачиваясь на высококачественных данных. Был использован аннотатор на основе BERT для выделения лучших токенов, и топ-12,5 миллиарда были использованы для дальнейшего обучения модели. Завершающий этап включал улучшенное предварительное обучение с использованием 5 миллиардов синтетических токенов, созданных с использованием высококачественных данных из второго этапа. Это позволило дополнительно улучшить способность модели генерировать точный код.
Итоговая модель Arctic-SnowCoder-1.3B, обученная всего на 555 миллиардах токенов, значительно превзошла другие модели подобного размера. На практических и сложных задачах программирования она показала высокую производительность, превзойдя конкурентов, обученных на гораздо больших объемах данных. Это подтверждает важность качества данных перед их количеством.
Заключение и рекомендации
Модель Arctic-SnowCoder-1.3B является примером того, как пошаговое улучшение качества данных в процессе предварительного обучения может значительно повысить производительность модели по сравнению с большими моделями, обученными на гораздо большем объеме данных. Этот метод демонстрирует важность согласования предварительного обучения с прикладными задачами и предоставляет практические рекомендации для будущего развития моделей. Успех Arctic-SnowCoder является доказательством ценности высококачественных данных, показывая, что тщательная курирование данных и генерация синтетических данных могут привести к существенным улучшениям в моделях генерации кода.
«`

























