«`html
Продвижение мультимодальных моделей визуального языка CogVLM2 для улучшения понимания изображений, видео и временной привязки в открытых приложениях
Большие языковые модели (LLM), изначально ограниченные текстовой обработкой, столкнулись с значительными трудностями в понимании визуальных данных. Это привело к разработке моделей визуального языка (VLM), которые интегрируют визуальное понимание с обработкой языка. Ранние модели, такие как VisualGLM, построенные на архитектурах BLIP-2 и ChatGLM-6B, представляли собой начальные усилия в мультимодальной интеграции. Однако эти модели часто полагались на поверхностные техники выравнивания, ограничивая глубину визуальной и языковой интеграции, подчеркивая необходимость более продвинутых подходов.
Практические решения и ценность
Последующие усовершенствования в архитектуре VLM, воплощенные в моделях, таких как CogVLM, сосредотачивались на достижении более глубокого слияния визуальных и языковых характеристик, тем самым улучшая естественную языковую производительность. Разработка специализированных наборов данных, таких как синтетический набор данных OCR, сыграла решающую роль в улучшении возможностей моделей OCR, позволяя более широкое применение в анализе документов, понимании GUI и понимании видео. Эти инновации значительно расширили потенциал LLM, стимулируя эволюцию моделей визуального языка.
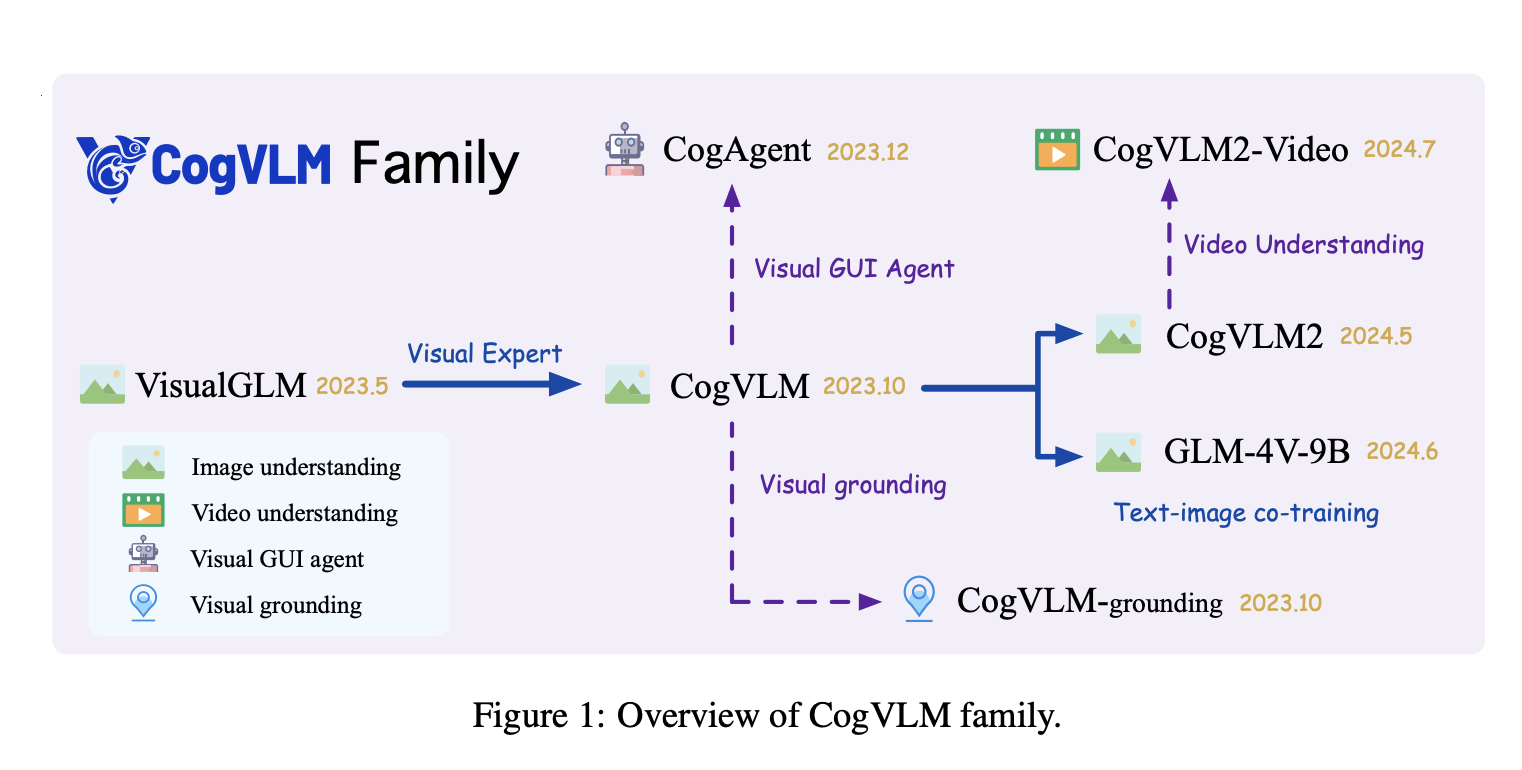
Эта научная статья от Zhipu AI и Университета Цинхуа представляет семейство CogVLM2, новое поколение моделей визуального языка, разработанных для улучшенного понимания изображений и видео, включая модели, такие как CogVLM2, CogVLM2-Video и GLM-4V. Усовершенствования включают архитектуру более высокого разрешения для распознавания изображений мелкой структуры, изучение более широких модальностей, таких как визуальное привязывание и агенты GUI, а также инновационные техники, такие как пост-уменьшение для эффективной обработки изображений. В статье также подчеркивается обязательство открытого исходного кода этих моделей, обеспечивая ценные ресурсы для дальнейших исследований и разработок в области моделей визуального языка.
Семейство CogVLM2 интегрирует архитектурные инновации, включая визуального эксперта и кросс-модули более высокого разрешения, чтобы улучшить слияние визуальных и языковых характеристик. Процесс обучения для CogVLM2-Video включает два этапа: настройка инструкций с использованием подробных данных описаний и наборов данных вопросов-ответов с коэффициентом обучения 4е-6, и настройка временной привязки на наборе данных TQA с коэффициентом обучения 1е-6. Обработка видеовхода использует 24 последовательных кадра, с добавлением сверточного слоя к модели Vision Transformer для эффективного сжатия видеофункций.
Методология CogVLM2 использует обширные наборы данных, включая 330 000 видеопримеров и внутренний набор данных для видео вопросов-ответов, для улучшения временного понимания. Оценочный конвейер включает в себя генерацию и оценку видеоподписей с использованием GPT-4o для фильтрации видео на основе изменений содержания сцены. Два варианта модели, cogvlm2-video-llama3-base и cogvlm2-video-llama3-chat, обслуживают различные сценарии применения, последний донастраивается для улучшенной временной привязки. Процесс обучения происходит на 8-узловом кластере NVIDIA A100 и занимает примерно 8 часов.
В частности модель CogVLM2, особенно модель CogVLM2-Video, достигает передовой производительности в нескольких задачах видео вопросов-ответов, превосходя бенчмарки, такие как MVBench и VideoChatGPT-Bench. Модели также превосходят существующие модели, включая более крупные, в задачах, связанных с изображениями, с заметным успехом в понимании OCR, понимании диаграмм и общем вопросно-ответном процессе. Комплексная оценка показывает универсальность моделей в задачах, таких как создание и суммирование видео, утверждая CogVLM2 как новый стандарт для моделей визуального языка в области понимания как изображений, так и видео.
В заключение, семейство CogVLM2 является значительным прорывом в интеграции визуальных и языковых модальностей, решая ограничения традиционных моделей только текста. Разработка моделей, способных интерпретировать и генерировать контент изображений и видео, расширяет их применение в областях, таких как анализ документов, понимание GUI и понимание видео. Архитектурные инновации, включая визуального эксперта и кросс-модули более высокого разрешения, улучшают производительность в сложных визуально-языковых задачах. Серия CogVLM2 устанавливает новый стандарт для открытых моделей визуального языка, с подробными методиками генерации наборов данных, поддерживающими их надежные возможности и будущие исследовательские возможности.
Проверьте статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и LinkedIn. Присоединяйтесь к нашему Telegram-каналу.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 50k+ ML SubReddit
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте CogVLM2: Advancing Multimodal Visual Language Models for Enhanced Image, Video Understanding, and Temporal Grounding in Open-Source Applications.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/ Этот ИИ ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
«`

























